오늘은 힙에 대해 써보려고 한다.
힙은
이진트리의 일종으로, 다음의 두 가지 속성을 만족하는 것을 말한다.
1. 트리 내 모든 노드의 부모-자식 관계에서 부모 노드의 키값과 자식 노드의 키값이 일정한 대소관계를 가지고 있어야 한다.
2. 완전이진트리로 구성되어야 한다.
각각이 어떤 것을 의미하는지 살펴보자.
먼저 첫번째 속성의 경우, 힙의 두 가지 유형인 최대힙과 최소힙에 대한 설명으로 이해할 수 있다.
최대힙이란 트리 내에서 부모 노드를 제외한 나머지 모든 노드들의 키가 그것의 부모 모드의 키보다 큰 힙을 말한다.
이에 대한 예시는 아래와 같다.
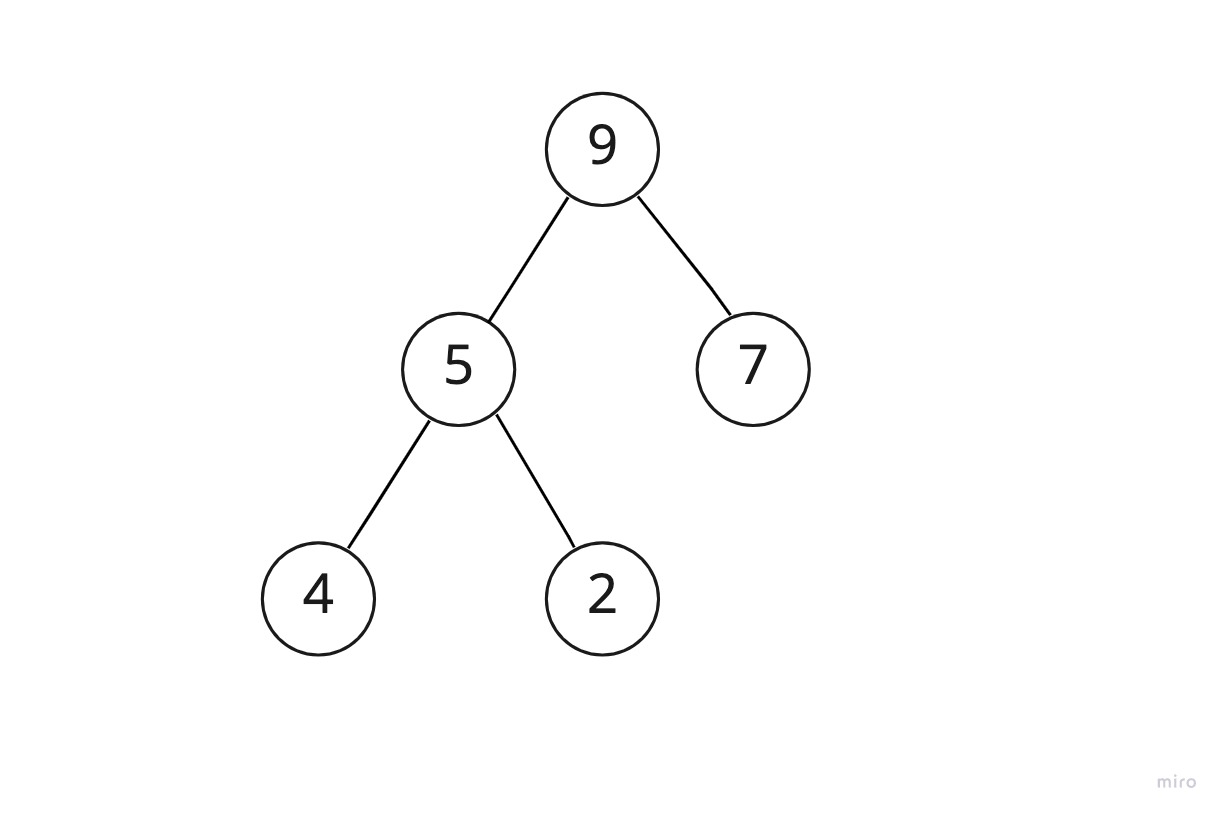
노드처럼 표시된 동그라미 안에 써있는 숫자를 키라고 할 때, 모든 부모 노드의 키가 자식 노드의 키보다 큰 경우이다.
여기서 모든 부모 노드의 키가 자식 노드의 키보다 작을 경우로 바뀌면 최소힙이 되는 것이다.
아래는 위의 최대힙을 최소힙으로 바꿔 본 것이다.
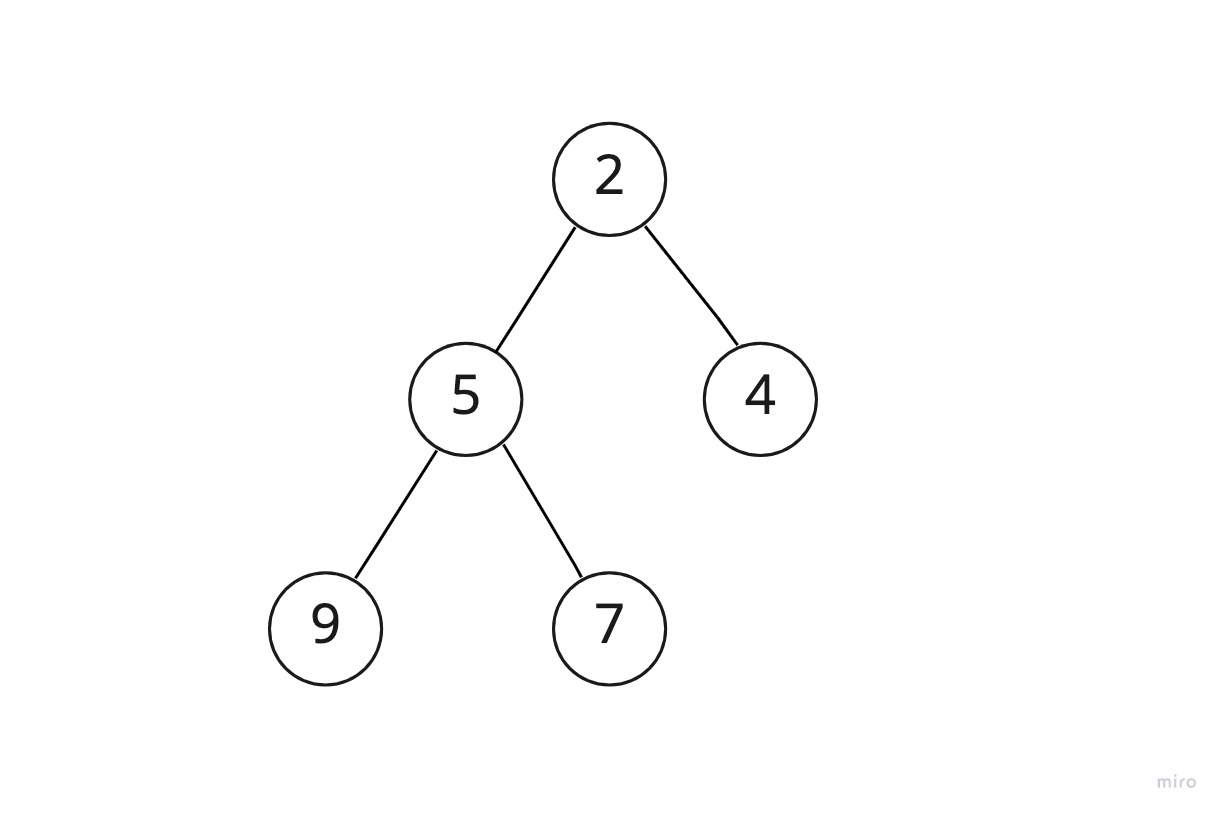
힙의 첫번째 속성은 이렇게 모든 노드의 부모-자식 관계가 최대힙이면 부모가 더 크도록, 최소힙이면 부모가 더 작도록 일정한 대소관계를 이루고 있어야 한다는 의미였다.
힙의 두 번째 속성은 완전이진트리이어야 한다는 것이다.
완전이진트리가 되려면 우선 모든 내부 노드가 자식을 두 개씩 가지고 있어야 한다.
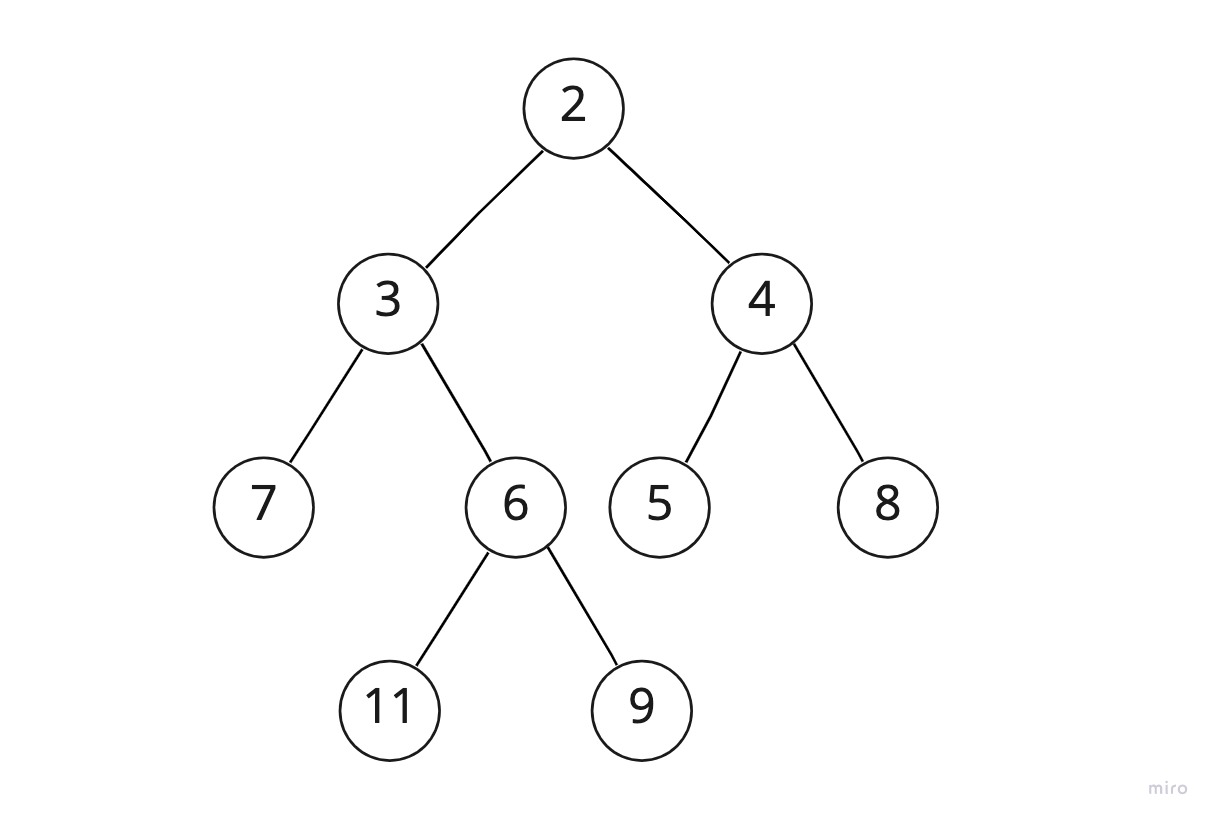
또한 가장 깊은 레벨의 노드들이 왼쪽부터 채워져있어야 한다. 이를 만족하는 트리의 예시는 다음과 같다.

아래는 완전이진트리가 아닌 경우에 대한 예시이다. 첫번째 트리는 모든 내부 노드가 두 개의 자식을 가지지 않은 경우이며, 두번째 트리는 가장 깊은 레벨의 노드들이 왼쪽부터 채워지지 않은 경우이다.

이렇게 힙은 최대힙이나 최소힙 속성을 만족하면서 완전이진트리인 자료구조를 말한다.
또한 힙에는 루트(root) 노드와 마지막 노드를 가리키는 두 개의 접근점이 있는데, 이를 이용하여 힙에 새로운 값을 추가하거나 삭제할 수 있다. 접근점이 어떤 식으로 사용되는지는 구현 과정에서 함께 보기로 하자.
쉬운 이해를 위해 구현에는 정수형 데이터가 들어있는 선형 배열을 사용하였으며, C언어를 사용했다.
1. 초기화
일반적으로 배열의 인덱스는 0부터 시작한다.
그러나 배열로 힙을 만들 때에는 0번 인덱스는 비우고 시작하는 것으로 생각하고 배열의 크기를 잡는 것이 정신건강에 좋다.
이유는, 배열의 시작 인덱스가 1일 경우 현재 노드의 인덱스를 이용하여 다음의 관계를 표현해낼 수 있게 되기 때문이다.
i : 현재 노드
i * 2 : 왼쪽 자식 노드
i * 2 + 1 : 오른쪽 자식 노드
floor(i / 2) : 부모 노드
따라서 n 개의 데이터를 입력받고자 한다면 배열의 크기는 n+1개가 되도록 하고 데이터는 1번 인덱스부터 넣도록 하자.
2. 힙 생성(삽입)
힙을 생성하는 방식은 두 가지가 있다. 삽입식과 상향식이 여기에 해당되는데, 이들은 데이터를 입력받는 방식에 따른 분류이다.
입력 데이터가 하나씩 들어오는 상황이라면 삽입식 힙 생성을 사용할 수 있고,
입력 데이터가 한 번에 들어오는 상황이라면 삽입식 힙 생성 또는 상향식 힙 생성을 사용할 수 있다.
먼저 삽입식 힙 생성은 입력되는 데이터에 대해 하나씩 삽입 작업을 해주는 것과 같다.
데이터 삽입 절차는 다음과 같다.
1. last가 가리키고 있는 곳을 새로운 노드가 추가될 곳으로 옮긴다.
2. last에 새로 입력받은 데이터를 넣는다.
3. 힙의 순서를 복구한다.
(last : 마지막 노드를 가리키고 있는 접근점, 마지막 노드: 레벨 순회로 데이터를 접근했을 때 제일 마지막에 접근하게 되는 노드)
배열로 구현할 경우 1번과 2번에 대해서는 어려울게 없다.
1번은 last가 가리키고 있는 인덱스값을 하나 증가시켜주면 되고, 2번은 증가된 위치에 데이터를 넣어주면 된다.
문제는 3번이 되는데, 앞에서 힙의 노드 간에는 순서가 존재한다고 언급했다.
그런데 임의의 데이터를 마지막 노드로 추가하게 될 경우 이것에 의해 힙 순서 속성에 위배되는 트리가 만들어질 수 있기 때문에 힙 순서 속성을 유지하기 위한 작업을 해야만 한다. 그림을 보면서 따라가보자.
우선 힙에 임의의 새로운 노드가 추가된 상황을 생각해보자.
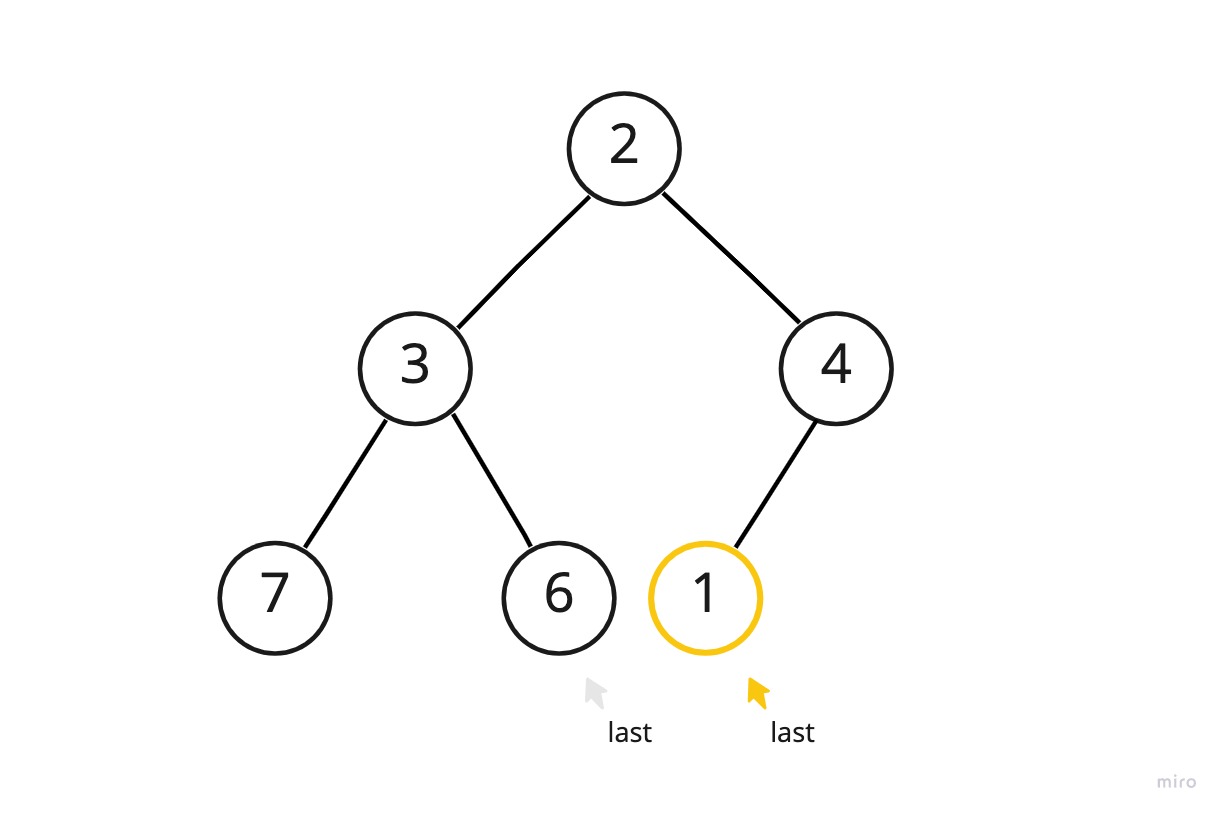
이는 기존의 최소힙에 새로운 데이터 1이 추가된 상황이다.
1이 추가되기 이전까지 last는 6을 가리키고 있었는데 데이터 추가를 위해 레벨 순위 상 다음 위치인 4의 왼쪽 자식 위치를 가리키도록 변경된 것이다. (단계1) 그리고 변경된 last 위치에 1을 넣었다. (단계2)
이 힙은 최소힙이어야하는데 1이 추가됨으로 인해 최소힙의 속성에 위배되어버렸다. 4보다 큰 데이터가 와야할 위치에 1이 저장되어있기 때문이다.
원래의 순서를 가지도록 복구하기 위해 새로 추가된 노드에서 시작하여 1보다 작은 노드가 나올 때까지 부모 노드를 타고 올라가면서 값을 맞바꾼다. 이 때 두 노드가 저장된 메모리 자체를 맞바꾸는 것이 아닌 노드 안의 데이터만을 맞바꾸는 식으로 구현하면 불필요한 수고를 덜 수 있다.
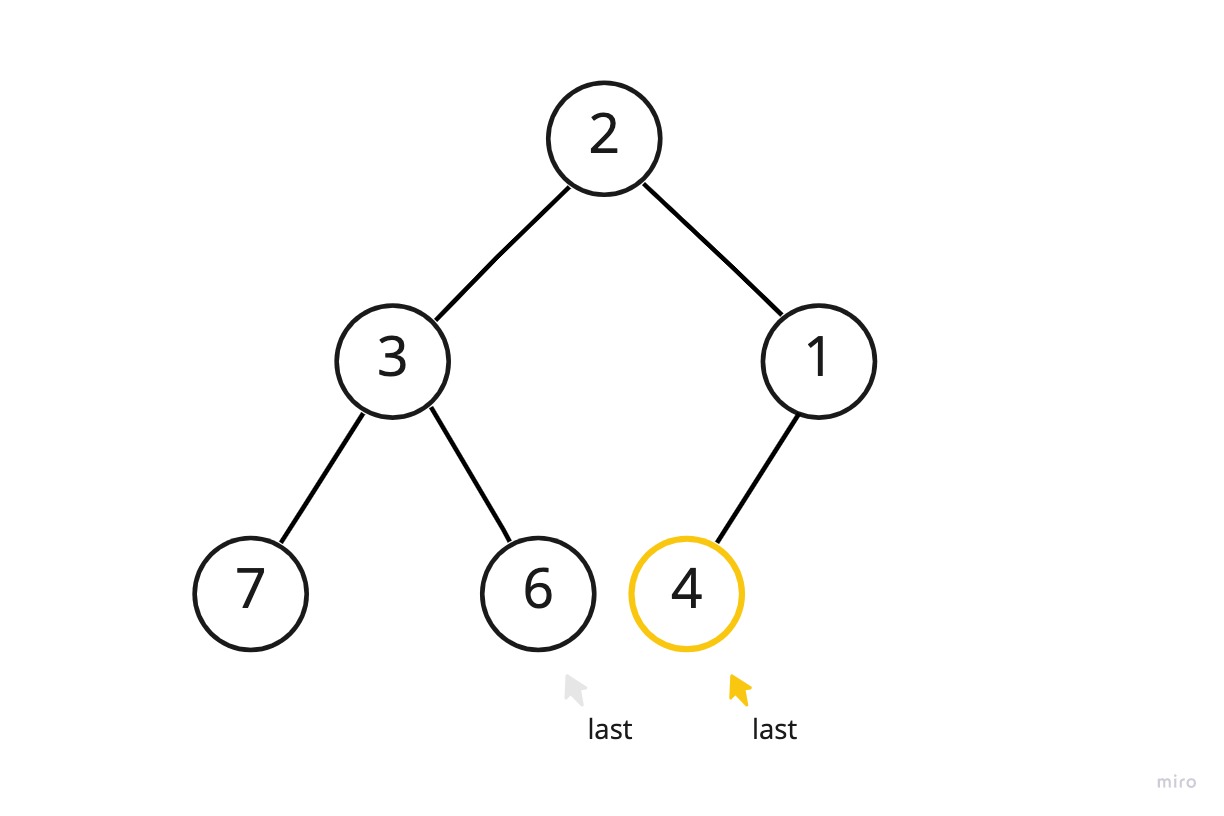

이 과정을 upHeap이라고 한다. upHeap 과정을 코드로 구현하면 다음과 같다.
// 재귀적 방식
void upHeap(int idx){
if(idx <= 1) return;
if(heap[idx] >= heap[idx/2]) return;
int tmp = heap[idx];
heap[idx] = heap[idx/2];
heap[idx/2] = tmp;
upHeap(idx/2);
}
// 비재귀적 방식
void upHeap(int idx){
int i = idx, tmp;
while(i > 1 && heap[i] < heap[i/2]){
tmp = heap[i];
heap[i] = heap[i/2];
heap[i/2] = tmp;
i = i/2;
}
}
위 3단계의 삽입 절차를 코드로 구현하면 다음과 같다.
// heap : 힙, N : 힙(배열)의 크기
void buildHeap(int key){
N += 1; // step 1
heap[N] = key; // step 2
upHeap(N); // step 3
}삽입식 힙 생성 방식을 사용할 경우 데이터를 하나씩 입력받을 때마다 이 함수를 호출하면 된다.
다음으로 상향식 힙생성은 입력 데이터가 전부 미리 주어져 있을 때만 사용할 수 있는 방식이다.
설명을 위해 방금 봤던 힙을 다시 가져와보자.
삽입식 힙 생성에서는 매번 새로운 노드가 추가될 때마다 일단 제일 마지막 last 위치에 넣고, 그 자리부터 최대 root 노드까지 계속 따라 올라가면서 값을 맞바꾸는 작업(이하 swap)을 했었다. 이러한 방식을 사용하여 한 번 데이터를 추가할 경우 발생하는 시간복잡도는 다음과 같다. (n: 힙에 존재하는 노드의 갯수)
1. last가 가리키고 있는 곳을 새로운 노드가 추가될 곳으로 옮긴다. => 배열의 경우 O(1)
2. last에 새로 입력받은 데이터를 넣는다. => O(1)
3. 힙의 순서를 복구한다. => O(log n) : 힙의 높이 log n , 최악의 경우 last부터 root까지의 모든 경로에 대해 swap을 해주어야 한다.
Total O(log n)
이 작업을 n 개의 데이터가 추가될 때마다 반복한다고 할 경우 전체 힙 생성에 걸리는 시간은 O(n log n)이 된다.
만약 여기서 미리 모든 입력 데이터가 주어져 있어 상향식 힙 생성을 사용할 수 있다고 할 경우 이에 걸리는 시간은 O(n)이 된다. 이것이 상향식 힙 생성을 사용하는 이유이다. 어떻게 O(n)의 시간안에 힙을 만들 수 있는지 보도록 하겠다.
상향식 힙 생성은 이름 그대로 아래에서부터 윗 방향으로 힙을 만들어나간다. 그림을 보자.

이러한 힙을 만들려고 한다. 이건 이미 힙이다. 그런데 지금은 힙을 "만들어나가는" 과정을 보기 위한 것이니까 이것을 힙이 아닌 일반 트리가 되도록 순서를 뒤바꾸겠다.
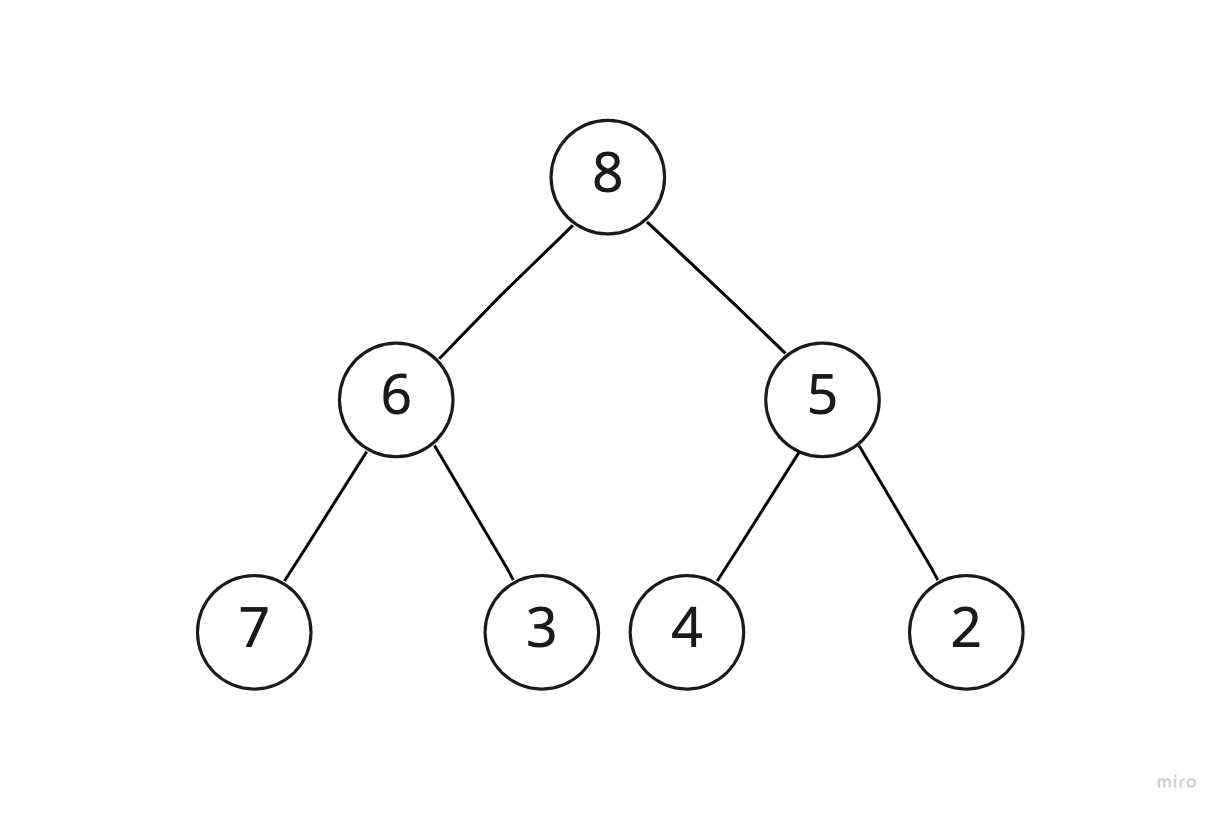
상향식 힙 생성 방식은 두 개의 부트리를 엮어 하나의 더 큰 트리를 만들어내는 개념으로부터 시작한다.
그리하여 트리 각각의 내부 노드를 root로 갖는 부트리로 생각하여 높이(h) - 1 깊이에 있는 부트리부터 차례대로 힙으로 만든다.
위의 트리를 부트리로 쪼갠다고 하면 아래와 같을 것이다.
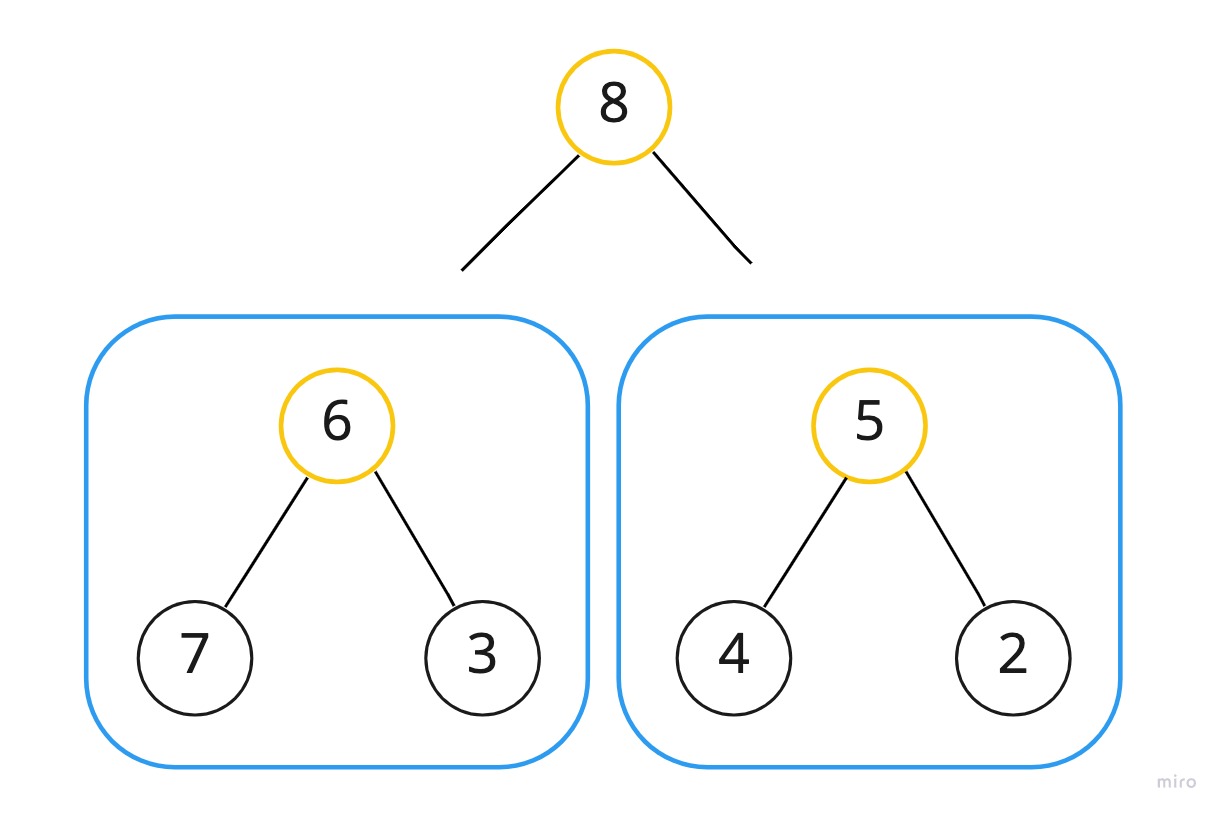
가장 작은 크기의 부트리부터 순차적으로 힙으로 만들고 -> 합치는 과정을 반복하여 최종적인 힙을 완성하게 될 것이며,
힙을 만들기 위해 힙 순서를 복구하는 함수를 downHeap이라고 한다.
downHeap에서는 특정 인덱스의 노드를 그것의 자식 노드들과 비교해나가며 힙 순서를 복구한다.
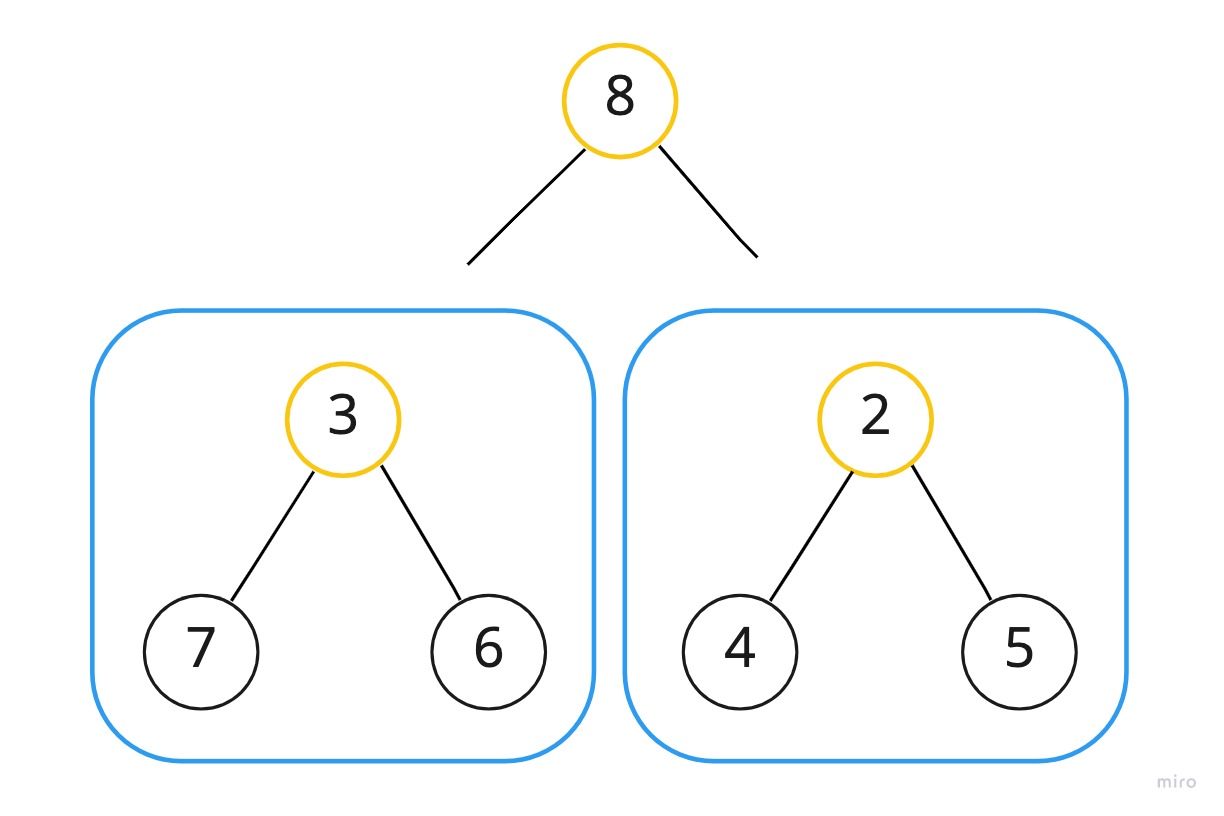
내부노드를 루트로 갖는 부트리의 힙 순서를 downHeap 과정을 통해 힙으로 만든 상황이다.
합칠 두 부트리가 준비되었으므로 8을 기준으로 하여 다시 한 번 downHeap을 수행한다.
(그림 상으로는 노드 8 과 부트리 3, 부트리 2가 각각 떨어져있는 것처럼 보이는데, 실제로는 그렇지 않다. 배열 내에서 일어나는 작업이며 각 노드의 데이터만 바뀌는 것이다.)


이 작업을 코드로 구현하면 다음과 같다.
void downHeap(int idx){
if(idx*2 > N) return;
int small = idx*2;
if(idx*2+1 > N){
if(heap[small] > heap[idx*2+1]) small = idx*2+1;
}
if(heap[small] >= heap[idx]) return;
int tmp = heap[small];
heap[small] = heap[idx];
heap[idx] = tmp;
downHeap(small);
}최소힙을 만드는 과정이기 때문에 조금이라도 더 작은 키를 가지고 있는 자식을 위로 올리려고 하고 있다. 이를 위해 small이라는 변수를 만들어 더 작은 값을 가지고 있는 자식의 인덱스를 구하도록 했다.
만약 최대힙을 만드는 과정이라면 두 자식 중 조금이라도 더 큰 키를 가지고 있는 자식의 인덱스를 big 변수에 넣어 사용하는 식으로 응용하면 될 것이다.
downHeap을 사용하여 상향식 힙 생성을 하는 전체 코드는 다음과 같다.
// heap : 힙, N : 힙(배열)의 크기
// 재귀적 방식
void buildHeap(int idx){
// 외부노드일 경우 비교를 끝낸다.
if(idx*2 > N) return;
buildHeap(idx*2);
buildHeap(idx*2+1);
downHeap(idx);
}
// 비재귀적 방식
void buildHeap(){
for(int i = N/2; i > 1; i--){
downHeap(i);
}
}이미 데이터가 주어진 경우에 대해 내부노드부터 알아서 다 스캔해나가는 방식이기 때문에 여러번 호출할 필요없이 한 번에 끝난다.
시간 복잡도
힙 생성을 하는 두 가지 방안에 대해 살펴봤다. 각각의 시간복잡도는 아래와 같다.
1. 삽입식 힙 생성 : O(n log n)
2. 상향식 힙 생성 : O(n)
삽입식은 위에서 다루었기 때문에 상향식에 대해서만 설명한다.
상향식 힙 생성의 동작 방식의 경우, downHeap 코드를 잘 살펴봤다면 캐치했겠지만 현재 노드의 키가 자식 노드의 키보다 이미 작아서(최소힙) 힙의 순서를 만족하는 경우 더 이상 진행하지 않고 return 한다.
이것이 자식쪽에서부터 시작해서 root로 올라가는 방식이다. 그러므로 부모 노드의 downHeap 과정이 진행될 때 자식 부트리의 경우 이미 힙으로 순서가 맞춰져있는 상태이므로, 비교되고 있는 노드들의 값의 순서에만 이상이 없다면 더이상 복구를 진행할 것이 없다.
이 과정이 이해가 되지 않는다면 아래와 같이 배열을 그린 뒤에 역방향(최소힙이라면 내림차순, 최대힙이라면 오름차순)으로 정렬된 데이터를 넣고 swap이 이루어질 때마다 하나씩 색칠해가면서 과정을 이해해보자. 이미 색칠이 되어있는 자리는 더이상 색칠할 일이 없거나 혹은 한 번 더 색칠하게 된다고 하더라도 그것이 겹치는 횟수만큼 다른 곳에 접근이 이루어지지 않은 원소가 존재할 것이다.

이번 글에서 다루었던 것은 힙에 대한 기본적인 개념과 구현 뿐이었는데, 힙을 이용하여 구현할 수 있는 다른 자료구조나 알고리즘도 있다.
대표적인 것으로 우선순위큐 ADT와 힙정렬이 있다.
이들에 대해서는 별도의 글에서 다루도록 하겠다.
'DataStructure' 카테고리의 다른 글
| 큐(Queue)의 정의와 구현 (0) | 2021.05.17 |
|---|---|
| 스택(Stack)의 정의와 구현 (0) | 2021.05.17 |


