일단 무작정 파일을 열어보니 그 안에서 HTTP 패킷같이 생긴 텍스트들이 여럿 발견되었고 문제 제목으로부터 network 관련된 것이라는 것을 참고하여 이를 Wireshark로 열어봤다.
그랬더니 기다렸다는 듯이 패킷들이 정렬되어 보여졌다! (나중에 알고보니 이 파일의 signature가 0A 0D 0D 0A로 pcapng 파일의 것임을 알았다.)
.pcap 파일의 signature
나같은 경우는 패킷분석을 위해 Wireshark를 살펴볼 때 주로 제일 먼저 찾아보는 것이 Protocol Hierarchy Statistics 이다.
현재 이 파일 내에 잡힌 패킷들에 어떤 프로토콜이 얼마나 많이 쓰였는지를 한눈에 파악하기 좋기 때문이다.
여기서 이 창을 통해 발견한 것은 HTTP 프로토콜 밑에 Malformed Packet이 있다는 것이었는데, Malformed Packet이란 패킷 파일이 손상되는 등의 문제로 제대로 보여지지 못하고 있는 경우를 말한다. 사실 패킷 분석하면서 이런 패킷이 있는 경우를 처음 봐서...무슨 일이 있었길래 이런 패킷이 있게 된건지 궁금해졌다.
그래서 해당 패킷의 Stream을 살펴보니.. 응답 패킷에 PNG 파일이 있다? 물론 PNG가 담길 수는 있는건데 왜 Malformed Packet이 표시가 뜬걸까
이 패킷은 HTTP 프로토콜을 사용하여 통신하다가 이런 오류가 생긴 것으므로 HTTP Stream에 어떤 문제가 생긴건지 좀 봐야겠어서 나머지 패킷들도 살펴봤다.
아까 그렇게 Malformed Packet 표시가 있던 패킷은 443번 패킷인데, 확실히 png 파일이 담긴 것은 맞는 것 같다. 파일 이름은 treasure1 이라고 한다. 그리고 그 밑에 이와 관련되어 있어 보이는 이름인 treasure2와 treasure3가 차례차례 보인다. 그런데 이 패킷들은 단순히 text/plain 형태이다.
우선 각 패킷 내에서 해당 파일들만 가져와 저장하여 빠르게 살펴봐야겠다. (HTTP object list 하단의 preview를 이용하면 빠르게 파일들만 저장할 수 있다! 처음에 그것도 모르고 TCP stream 다 뒤져가면서 내려받았었던 기억이...)
내려받은 각 파일들을 HxD Editor로 열어봤다.
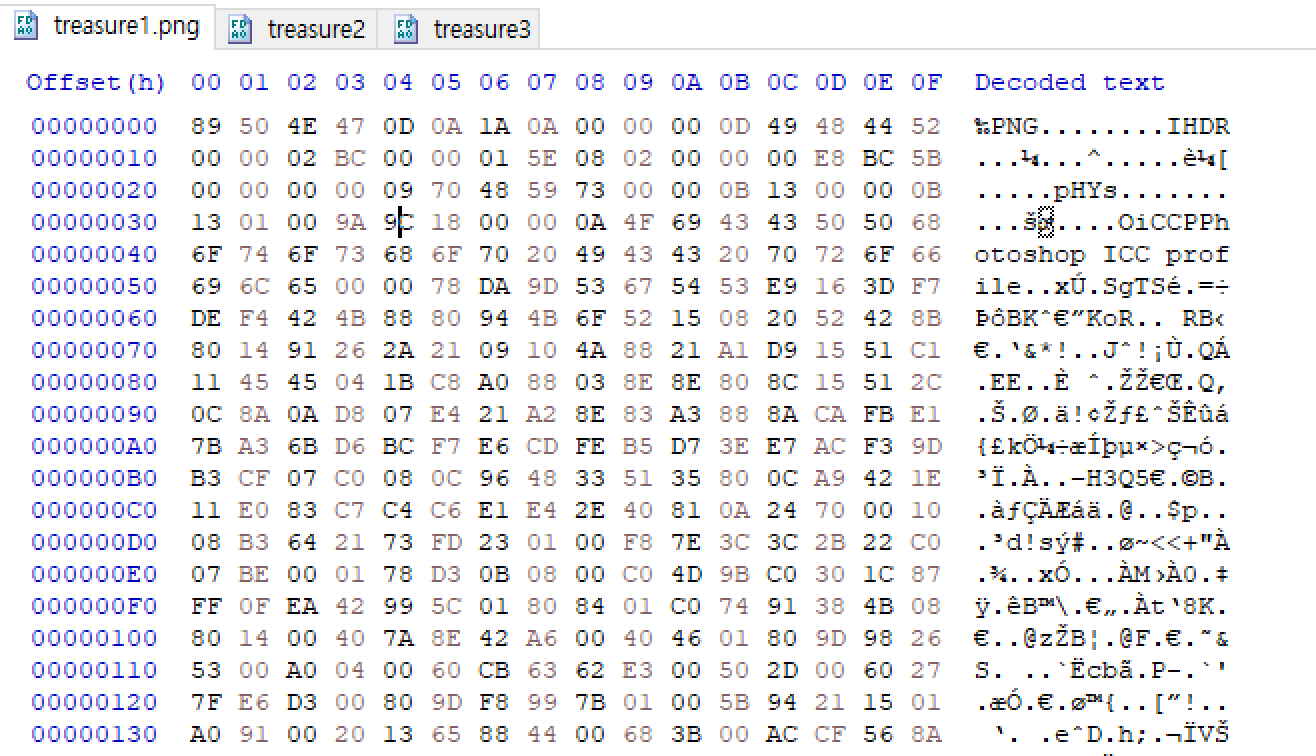
treasure1.png
그리고 treasure1.png 파일의 Signature가 잘 있는지 봤는데, Header Signature인 89 50 4E 47 0D 0A 1A 0A 는 찾을 수 있었지만 Footer Signature인 49 45 4E 44 AE 42 60 82 는 찾을 수 없었다. (File Signature 참고: http://forensic-proof.com/archives/323 )
이게 Malformed Packet의 원인이었던 것 같다. 이 파일만 실행시켰을 때에도 뭔가 매우 불편해보이는 이미지를 볼 수 있었다.
나머지 두 파일도 정체가 뭐길래 2, 3번의 이름이 붙은 것인지 봐야겠다.
treasure2treasure3
treasure2에서 발견한 것은 수 많은 00 과 그 사이에 드물게 있던 몇몇 hex들이었고, treasure3에서 발견한 것은 수 많은 00 과 그 끝에 있던 IEND, Footer Signature였다!
treasure2가 모두 0으로만 가득차있었더라면 버리고 3만 쓰고자 했을 수도 있었을텐데..ㅎ 중간에 있던 데이터들이 소중하게 보여서 모두 연결해보기로 했다.
Header Signature가 있던 treasure1을 제일 처음에 붙이고 Footer Signature가 있던 treasure3을 당연히 제일 마지막에 붙여야 할 것 이다. 남은 treasure2는 두 파일 사이에 위치시켰다. HxD 에서 [도구] - [파일 도구] - [연결] 을 이용하면 파일을 손쉽게 연결시킬 수 있다.
이렇게 해서 연결한 파일에 .png 확장자를 붙여서 열면 key값이 담긴 이미지를 볼 수 있고, 이를 이용하여 해쉬값을 만들면 성공이다.
treasure1, 2, 3의 존재를 발견한 후에 이 파일을 내려받는 방식으로 TCP Stream의 패킷 내용을 RAW로 저장한 다음, 그 안에서 초반 ~ 0A 0D 0A 0D 까지를 싹 다 지운 데이터를 사용하여 이어붙이기를 반복했었다. (이유는 이전에 어떤 다른 문제에서 그런식으로 패킷내용으로부터 데이터를 카빙하는 것을 보았기 때문)
근데 뭐가 문제인건지 그렇게 해서 이어붙이면 제대로된 파일이 만들어지지 않았다. 앞으로 자유롭게 손카빙 할 수 있을 정도의 실력이 되기 전까지는 가능한 preview...로 정신적 고통을 덜어야겠다ㅠ