이 글은 SQLite File structure 분석에 이어지는 글이며,
SQLite에서 레코드를 삭제할 경우 파일 내에 생기는 일과 그렇게 삭제된 레코드가 관리되는 방식을 다룬다.
레코드는 Leaf page에 저장되어 있다. 따라서 레코드 삭제 요청이 들어올 경우 가장 먼저 변화가 일어나는 곳도 Leaf page이다.
Page의 구조가 아래와 같다는 것을 고려할 때, Leaf page에서 어떤 레코드가 삭제되면 해당 레코드를 가리키던 cell offset의 값도 삭제될 것임을 짐작해볼 수 있다. 그렇다면 기존의 cell offset이 가리키고 있던, 삭제된 cell 공간은 추후 데이터의 삽입이 일어날 때 재사용이 될까? 효율을 위해서라면 높은 확률로 재사용될 텐데 이를 위해 어떤 체계를 쓰고 있을까?

이러한 물음에 대한 답을 찾고자 데이터베이스 파일 내부를 직접 들여다보았다.
테스트를 위해 7개의 레코드를 갖는 테이블을 만들었다.
이 레코드들은 모두 하나의 Leaf page 안에 있는 상황이다.

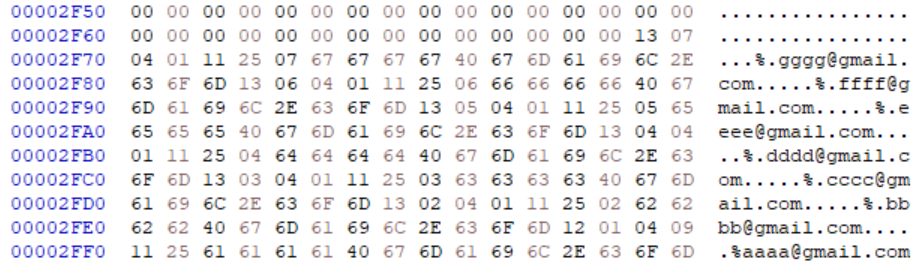
현재 page header의 offset 0x3에 위치한 number of records의 값은 7이며,
7개의 레코드는 첫번째부터 순서대로 다음의 offset을 갖고 있다.
-> 0xFEC, 0xFD7, 0xFC2, 0xFAD, 0xF98, 0xF83, 0xF6E
이 상태에서 제일 마지막 offset인 0xFEC에 위치한 순서상으로는 첫번째 레코드(aa..)를 삭제해보았다.


page의 처음으로부터 offset 0x08에 위치했던 0xFEC가 사라지고, 그 자리를 이후에 위치한 offset값들이 차지하고 있는 것을 알 수 있다. 이와 함께 number of records 값이 6으로 변했다.
여기서 cell offset 배열 내의 한 원소를 삭제할 때 그 이후의 값들을 하나씩 당겨오는 방식으로 원소를 삭제한다는 것을 알 수 있다.
삭제된 셀이 위치해있던 0xFEC에서 일어난 변화를 보면, 첫 4 바이트가 4바이트의 어떤 정수로 덮어씌워졌으며 그 이후의 데이터는 여전히 파일에 남아있는 것을 볼 수 있다.
이 덮어씌운 정수가 어떤 값을 의미하는지를 확실히 하기 위해 이번에는 중간에 있는 데이터를 삭제해보았다.


offset 0xFC2 에 위치해있던 (초기데이터 기준으로) 세번째 레코드(cc..)를 삭제했다.
page header와 cell offset 배열에 일어난 변화는 이전과 동일했는데, 레코드의 첫 4바이트가 또 다른 어떤 정수로 바뀐 것을 볼 수 있다.
가만 보면 4 바이트 중 상위 2 바이트는 이 다음에 위치한 삭제 레코드의 offset이고, 하위 2 바이트는 이 다음에 위치한 삭제되지 않은 레코드와 현재 레코드와의 offset 차이값을 나타냄을 알 수 있다.
(0x2FC2 + 0x15 = 0x2FD7이다. -> 두번째 레코드의 offset)
이러한 가정을 조금 전에 시도했던, page의 끝에 위치한 레코드를 삭제했을 경우에 적용해보면..
이후 위치한 삭제 레코드가 없으므로 상위 2 바이트의 값이 0이었고, 이후 위치한 삭제되지 않은 레코드의 값은 이 다음 페이지와의 offset 차이값을 가지고 있었다는 것으로 그 정수값의 의미를 유추해낼 수 있다.
(0x2FEC + 0x14 = 0x3000이다. -> 세번째 페이지의 offset)
여기에 SQLite에서 page간의 관계가 B+ Tree 구조로 이루어져 있다는 것까지 함께 고려한다면 위 가정에 신뢰를 더할 수 있다.
(B+ Tree는 Leaf 노드끼리 연결리스트 구조를 이루고 있어 이들간의 선형 탐색이 가능하도록 되어있다.)
그렇다면 이렇게 삭제된 노드의 저장공간이 어떻게 활용되는지 확인하기 위해 새로운 레코드 하나를 추가해보겠다.

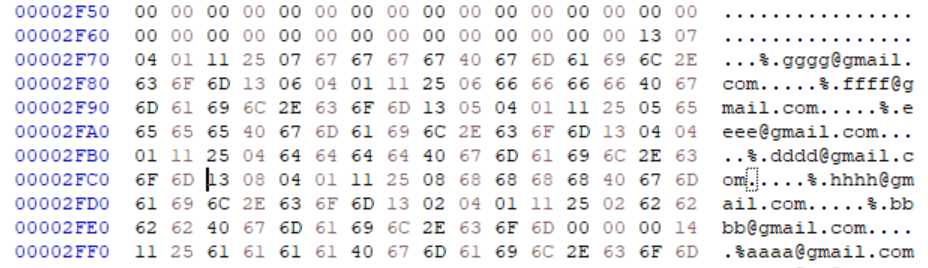
그러자 cell offset 배열의 마지막 위치에 익숙한 offset 0xFC2가 추가된 것을 확인할 수 있다.
이는 바로전에 삭제했던 레코드(cc..)의 offset이었으며, 새롭게 들어온 레코드(hh..)의 저장도 이곳에 이루어진 것을 확인할 수 있다.
삭제된 레코드의 offset은 분명 cell offset 배열에서 삭제되었는데 어떻게 이 offset을 다시 찾아갈 수 있었을까?
답은 page header의 offset 1에 위치한 offset of first block of free space 값에 있다.
눈치가 빨랐다면 이미 알았겠지만 사실 지금까지 레코드를 삭제하는 동안 이 값은 그에 따라 계속 변하고 있었다.



이는 마치 다음과 같은 연결리스트가 있을 때 가장 끝에 있는 노드, 즉 가장 빠른 offset을 가지고 있는 노드를 pointer가 가리키고 있는 구조로 생각할 수 있다.
여기서의 pointer 방식이 page header의 offset 1에 값을 저장하는 것이라고 생각하면 되는 것이다.
이 때, offset 값을 기준으로 오름차순이 되도록 새로운 노드가 추가되며 그렇기 때문에 레코드를 삭제한다고 해서 꼭 pointer의 값이 달라지는 것은 아니다. (pointer는 가장 빠른 offset의 free block을 가리키고 있기 때문.)
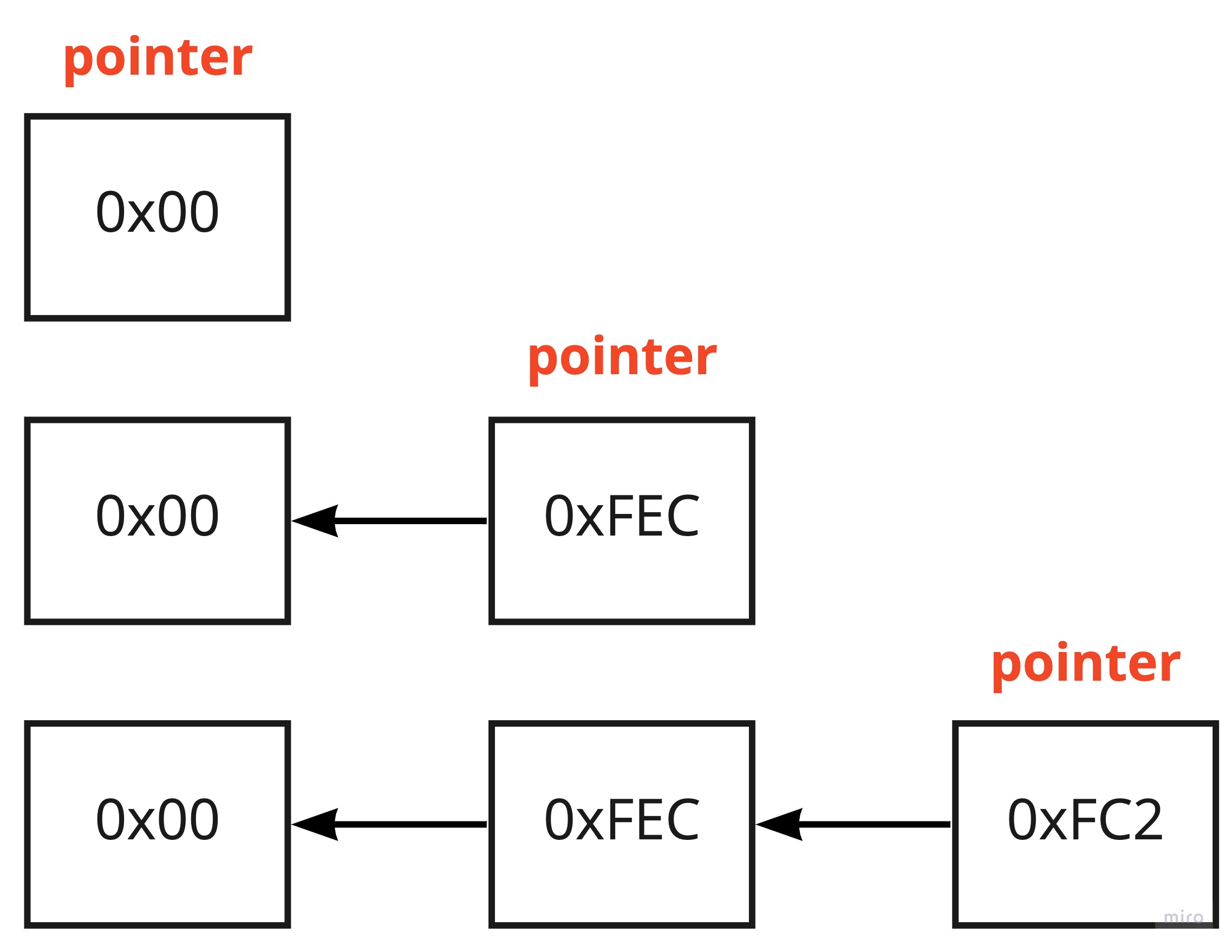
그러다 새로운 레코드가 추가되면 이 pointer가 가리키고 있는 offset에 해당 레코드를 저장하는 것이다.
이렇게 데이터를 삭제하고 삭제한 위치를 관리하는 시스템을 이용한다면 삭제된 데이터를 복구하는 작업도 가능하게 된다.
앞서 봤던 것처럼 연결리스트 구조를 이용하여 삭제된 데이터가 저장된 위치만을 순회할 수 있고,
데이터가 삭제된다고 하더라도 해당 레코드의 상위 4 바이트만 변경이 되지 그 이후의 데이터는 그대로 남아있기 때문이다.
그래서 원래 이 삭제 메커니즘을 분석했던 이유도 Chrome browser History를 복구해보기 위한 선행 지식이었기 때문이었는데,
알게 된 지식을 이용하여 History 데이터베이스를 따라가보니 안티포렌식 처리가 되어 있음을 확인해버렸다..
슬픈 결과이지만 그를 따라갔던 과정이라도 적고 마무리 하려고 한다.
Chrome 96.0 기준으로 확인한 결과이며, 언제부터 이것이 적용되었는지는 모르겠지만 이전 버전에서는 다른 결과를 보일 수도 있다.
아래는 내 Chrome local에 저장된 History 데이터베이스 내에 있는 urls 테이블의 한 Leaf page를 가져온 것이다.

page header offset 1 값에 의해 마지막으로 삭제된 레코드의 offset이 0x50A임을 알 수 있다. 해당 위치로 따라가보았다.
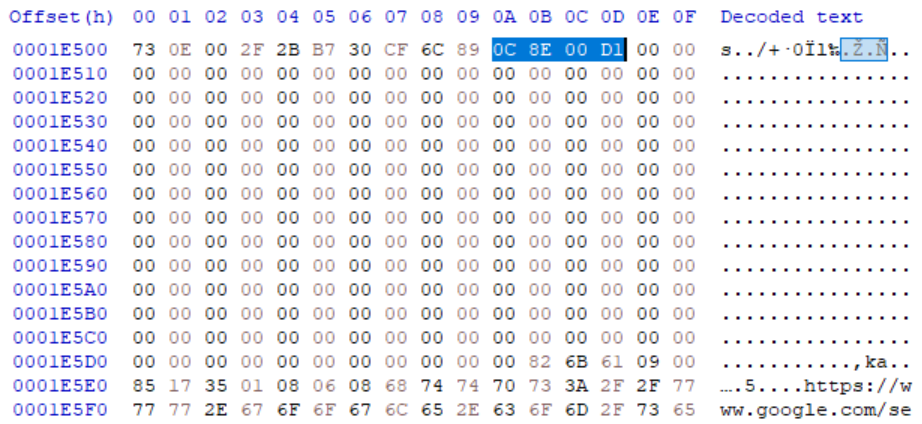
예상했던대로 첫 4바이트는 (다음 free block의 offset 2바이트 : 다음 cell과의 offset 차이값 2바이트) 로 이루어진 값이 저장되어있다.
그런데 문제는 4바이트 이후에 저장되어 있어야할 데이터가 모조리 0으로 채워져있다는 점이다.
다음 free block의 offset인 0x1E000 + 0xC8E 로도 쫒아가 나머지도 모두 같은 상황인지 확인했다.

마찬가지였다.
이 후 다른 테이블로 넘어가 몇개의 free block을 더 확인하였는데.. 삭제된 위치의 첫 4바이트 이후 값은 모두 0으로 지워져있었다.
Chrome History 복구 모듈을 만들어보고자 하는 목적으로 시작한 공부였는데, 끝이 이렇게 날 줄은...
아쉬우니 다음에 Chrome이 아닌 다른 SQLite 데이터베이스 파일의 복구 모듈을 만들어보는 것도 도전해봐야할 것 같다.
'DFIR > Forensic Artifacts' 카테고리의 다른 글
| Windows Registry 개요 및 주요 아티팩트 정리 (0) | 2023.07.09 |
|---|---|
| Windows Registry Timezone과 SYSTEM Control registry 백업 원리 분석 (0) | 2023.06.30 |
| SQLite File Structure 분석 (0) | 2022.01.03 |
| Chrome Disk Cache Structure 분석 (0) | 2021.11.14 |
| [Storage] 하드디스크 구조 (0) | 2021.08.11 |