SQLite는 하나의 데이터베이스를 하나의 파일로 관리한다.
그에 사용되는 데이터베이스 파일은 다음의 구조로 이루어져 있다.

1. Header page
1) Database header (size: 0x64)
: Database에 대한 정보를 가지고 있다.
- DB size, Text Encoding 방식, page size, number of pages 등
2) Schema Table
: Database내에 있는 table, index 테이블에 대한 스키마 정보를 가지고 있다.
- 테이블 유형(table / index), root page offset, CREATE 시 사용한 query 텍스트
- 데이터베이스 내에 있는 하나의 테이블에 대한 정보가 Schema Table의 하나의 레코드로 저장되어 있다.
** 여기 자체로 또 하나의 page 구조를 보이고 있어서, 여기의 상위를 Header page라고 표현했지만
사실상 그냥 Database file header와 Schema page가 있다고 생각하는 게 더 간편하다.
2. Interior Page, Leaf Page (B+Tree)
: Schema Table에서 얻을 수 있는 root의 offset을 이용하여 각 테이블의 root page에 접근할 수 있다.
테이블 내에 저장된 레코드가 하나의 page를 넘어가지 않을 경우 단일 leaf page에 저장되고 root page offset은 이 leaf page를 가리키게 된다. 그러나 레코드의 개수가 하나의 페이지를 넘어설 경우 여러 leaf page를 통해 저장되고 이 여러 leaf page들의 offset을 포인터로 가지는 interior page의 offset이 root page offset에 저장된다.
3. Overflow Page, Free Page
- Overflow Page : 데이터를 한 페이지에 전부 담을 수 없는 경우 생성되는 페이지
- Free Page : overflow page를 가지고 있던 레코드가 삭제된 경우 overflow가 free page로 전환되어 생기는 페이지
여기까지 설명한 데이터베이스 구조를 도식화시키면 다음과 같다.
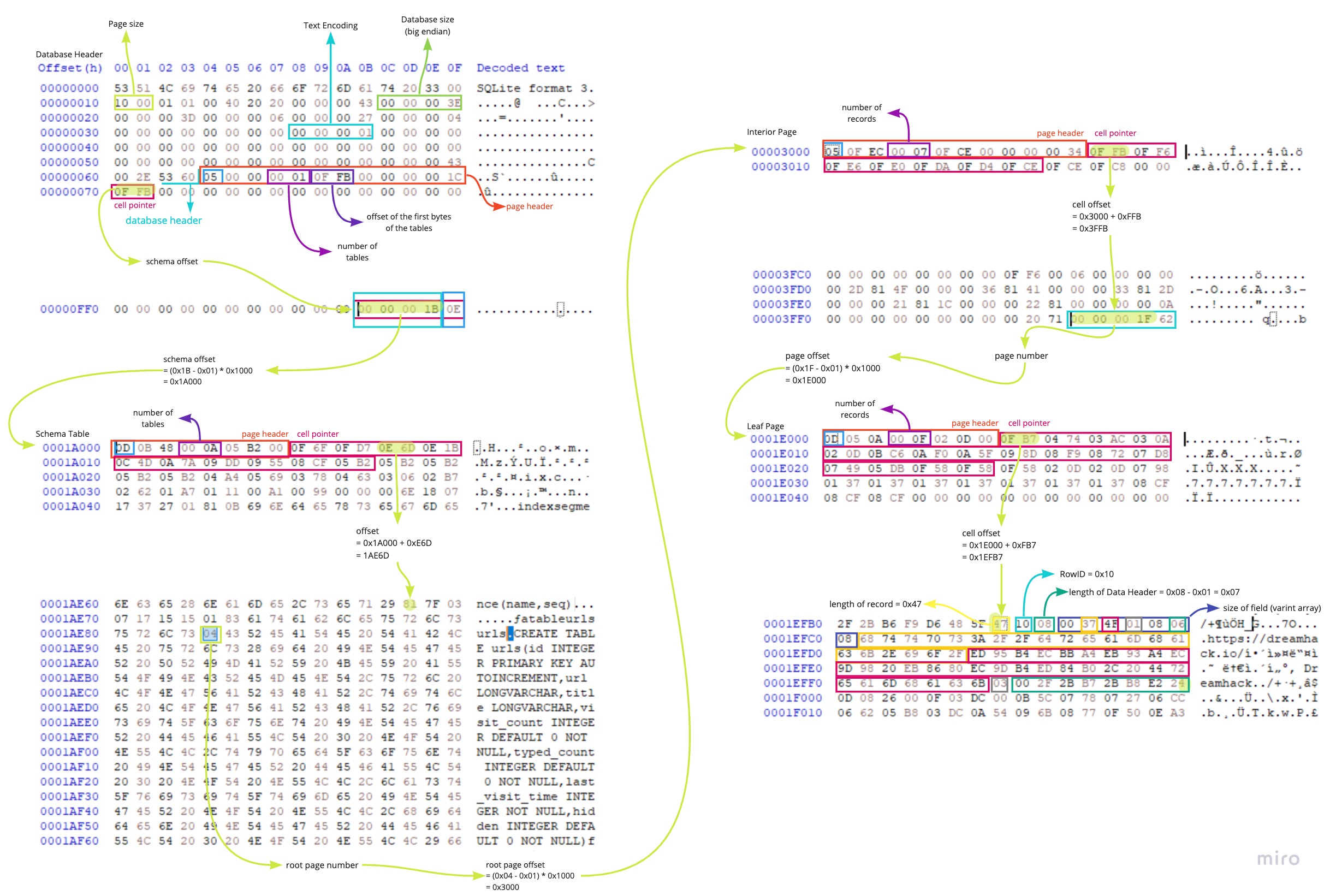
아래는 Header page에 있는 Database Header와 그 이후의 Schema Table을 가리키는 header 정보를 캡처한 것이다.
header 정보를 이용하여 Schema를 찾아가는 법에 대해서는 곧바로 나올 page 구조에 대해 이해하면 알 수 있다.
위에서 page라는 용어를 계속 사용하였는데, 이는 SQLite에서 채택한 구조인 B+Tree에서의 하나의 노드라고 생각하면 된다.
데이터베이스 파일 내에서 사용되는 페이지의 유형은 Header Page를 제외하고 크게 Interior page와 Leaf page로 나눌 수 있다.
Interior page에는 Leaf page를 가리키는 cell만이 존재할 뿐 실제 DB 데이터는 모두 Leaf page에 저장되어 있다. 따라서 레코드 탐색 시 각 table의 Schema Table에 있는 root page offset에서 시작하여 Leaf page가 나올 때까지 순회한다.
Leaf page도 Interior page와 구조는 비슷하나, cell에 Leaf page의 offset이 아닌 실제 데이터베이스에 저장된 데이터가 있다. 하나의 cell에는 데이터베이스 내의 하나의 레코드에 해당하는 데이터가 있다.
이러한 Page는 다음의 구조로 구성된다.
1. Page Header
(size: 0x0C - Interior / 0x08 - Leaf)
: Page에 대한 정보를 가지고 있다. page의 유형에 따라 header의 크기가 달라진다.
- Offset 0 : 0x05 - Interior / 0x0D - Leaf
2. Cell Offset
(2 bytes array)
: 배열 형태로 각 cell에 대한 offset을 저장한다.
배열에 저장된 각 offset이 가리키고 있는 cell은 페이지의 마지막부터 채워진다.
page header와 cell offset이 페이지 상단부터 채워지고, cell의 데이터가 페이지의 하단부터 채워지는 구조이다. 이것에 의해 페이지의 중간에 free space가 생기게 된다.
파일 구조를 따라가다 보면 number와 offset이라는 용어를 마주하게 된다.
number는 주로 page를 찾아갈 때 사용되고, offset은 셀을 찾아갈 때 사용된다.
이 둘은 계산하는 방법이 조금 다른데,
page number로부터 파일 내에서의 page offset을 구하기 위해서는 다음의 수식이 사용된다.
page offset = (page number - 1) * page size
page size는 database header의 offset 0x10에 있는 2 bytes를 통해 알 수 있다.
주어진 cell offset으로부터 파일 내에서의 offset을 구하기 위해서는 다음의 수식이 사용된다.
(파일) cell offset = 해당 page의 시작 offset + (주어진) cell offset
여기까지의 내용을 가지고 Header page에서부터 특정 테이블의 record에 접근하는 과정을 따라가 보면 다음과 같다.
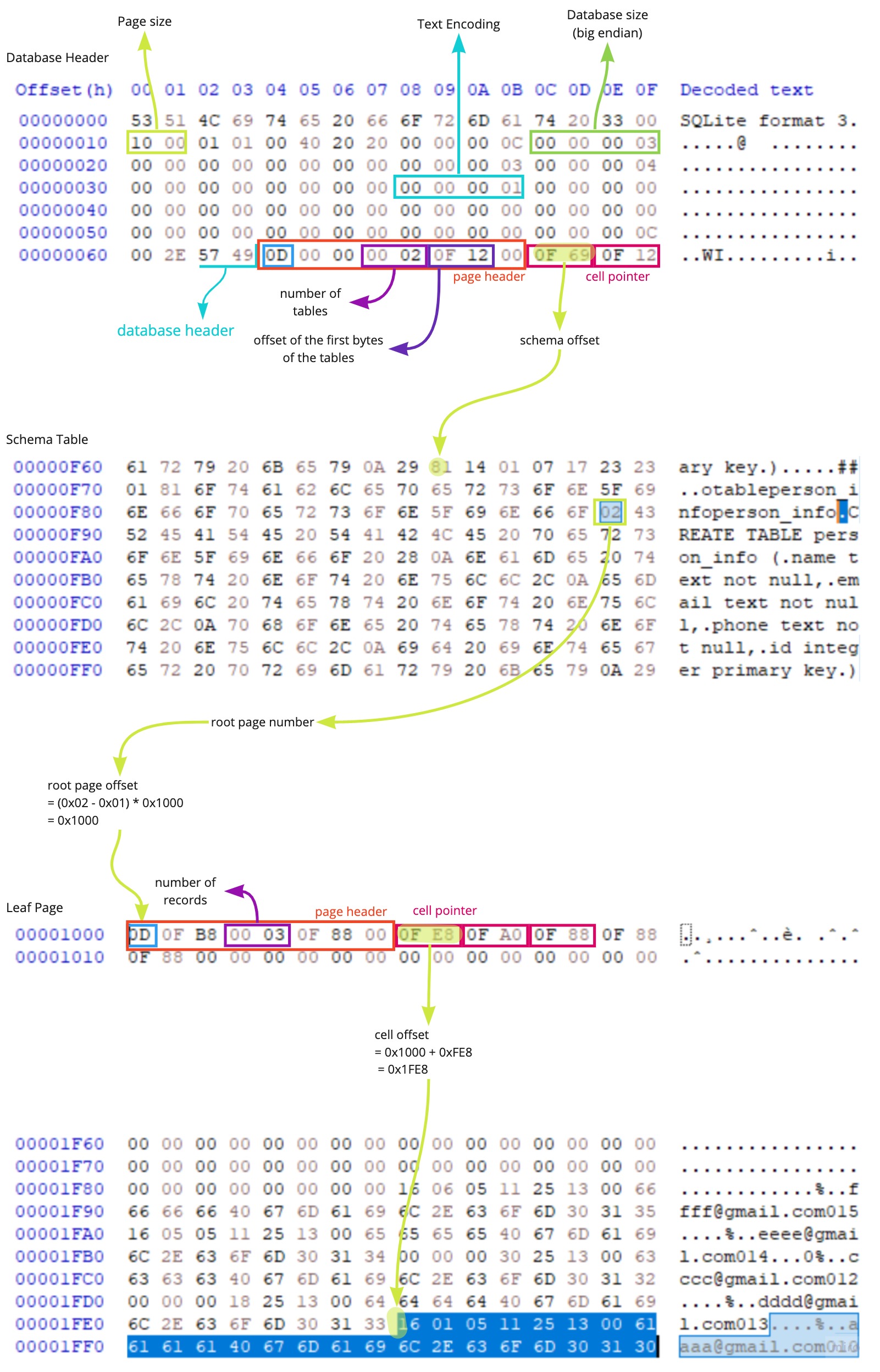
연두색으로 형광표시해둔 곳을 대표로 따라가 보았다.
여기서는 root page로 곧바로 leaf page가 나와서 금방 record에 도달할 수 있었는데, interior page가 나오는 경우에 대해서도 보자면 다음과 같다.
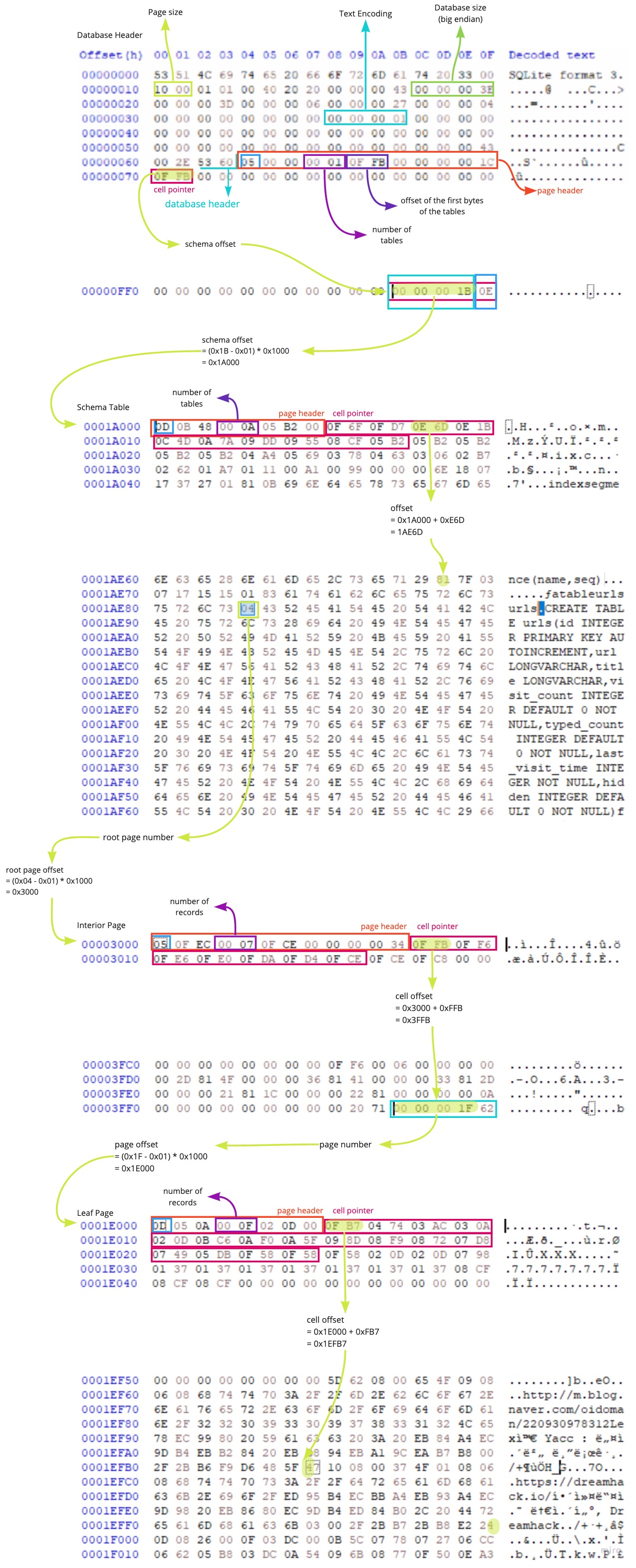
마지막으로 레코드 안에 있는 각 칼럼의 데이터를 파싱 하기 위한 레코드 구조에 대해 살펴보려고 한다.
SQLite에서는 파일 용량을 절약하기 위한 방법으로 variable length integer(일명 varint)를 사용한다.
이는 1~9 byte의 크기를 가지는 가변 길이 정수를 말하는데, 각 바이트의 MSB는 다음 바이트의 유무를 나타내는 비트로 사용하고 실제 데이터는 나머지 7개의 비트에 저장한다. MSB가 1일 경우 표현하려는 정수가 7비트의 표현 범위를 넘어가 다음의 추가적인 바이트를 사용한다는 의미를 가지며, 0일 경우는 해당 바이트가 해당 필드의 마지막 바이트라는 것을 의미한다. 이러한 표현방식을 이해하기 위해 다음의 예제를 살펴보자.
ex. varint 0x8106 이 나타내는 정수는?
0x8106 = 10000001 00000110 (2진수)
첫 번째 바이트는 MSB가 1이고 1의 데이터를 가진다. 첫 번째 바이트의 MSB가 1인 것에 의해 두 번째 바이트도 살펴봐야 되는 상황이 되었는데, 두 번째 바이트의 MSB는 0이므로 더 이상의 추가적인 바이트를 사용하지 않는다.
따라서,
(첫 번째 바이트의 하위 7비트) : (두 번째 바이트의 하위 7비트) = 1 0000110 (2진수) = 0x86 의 정수를 나타내는 varint임을 알 수 있다.
(콜론(:)은 두 묶음의 7비트들을 나란히 이어붙이는 것을 의미한다.)
아래의 record 구조에 등장하게 되는 cell header와 record의 length of data header에서 이러한 varint 타입을 사용하여 값을 표현한다.
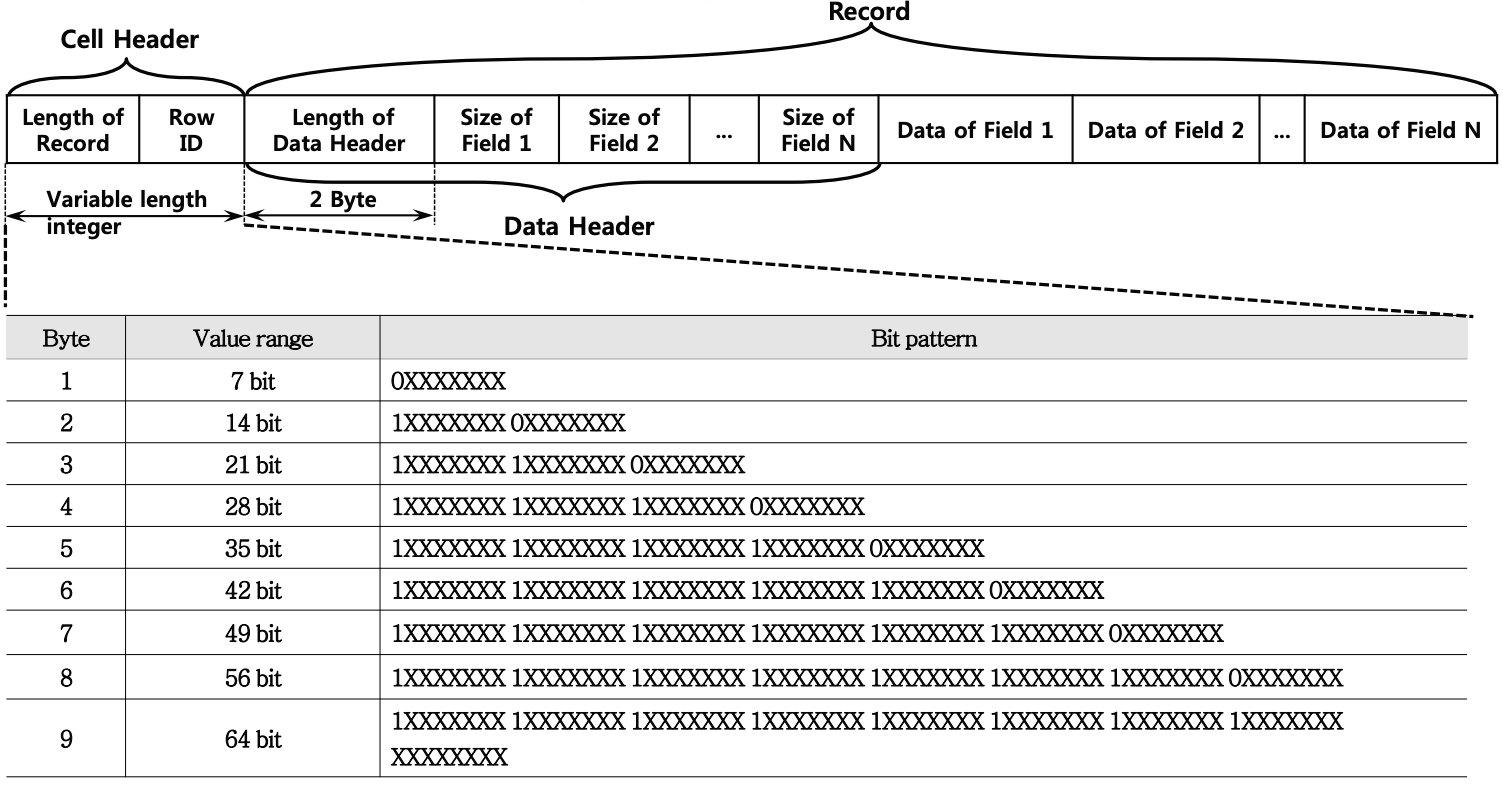
cell offset을 통해 레코드에 접근한 후 순차적으로 Length of Record와 Row ID의 값을 구하고 이어서 Length of Data Header도 구할 수 있게 된다. 이때 구하게 되는 Data Header의 길이는 Length of Data Header 필드가 차지하는 길이도 포함된 값이므로, data field만의 길이를 구하기 위해서는 Length of Data Header의 값에서 이 필드가 차지하는 길이만큼을 빼주어야 한다.
이러한 작업을 통해 data field의 갯수를 구하게 된 뒤에는 이 갯수만큼 data header의 값을 순차적으로 읽고 다시 그 값만큼의 데이터를 읽어 나가는 방식으로 데이터를 파싱하면 된다.
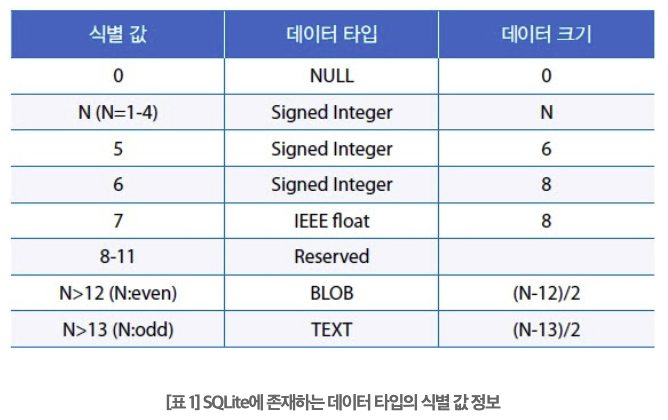
그 과정에서 만나게 되는 data header의 size of field에는 각 칼럼에 해당하는 데이터 타입 및 크기에 대한 정보가 저장되어 있다.
각 값에 따른 데이터 타입 및 크기에 대한 정보는 다음의 표를 참고하면 알 수 있다.
여기까지의 정보를 이용하면 아래와 같이 record 내의 필드값을 파싱해낼 수 있다.

이 글에서 다룬 내용을 이용하여 하나의 테이블 내에 있는 하나의 레코드의 값을 구하는 흐름을 정리하면 아래와 같다.
'DFIR > Forensic Artifacts' 카테고리의 다른 글
| Windows Registry 개요 및 주요 아티팩트 정리 (0) | 2023.07.09 |
|---|---|
| Windows Registry Timezone과 SYSTEM Control registry 백업 원리 분석 (0) | 2023.06.30 |
| SQLite record 삭제 체계 분석과 record 복구까지... 하려다 안티포렌식까지 접하게 된 일 (0) | 2022.01.04 |
| Chrome Disk Cache Structure 분석 (0) | 2021.11.14 |
| [Storage] 하드디스크 구조 (0) | 2021.08.11 |










