운영체제는 복수의 프로세스들을 관리하는 과정에서 여러 문제에 직면하게 되는데
그중 가장 큰 문제는 race condition(경쟁상태), 쉽게 말해 동기화이다.
두 개 이상의 프로세스가 동시에 공유 자원에 접근할 경우 명령어 실행 순서(프로세스 수행 순서라고도 볼 수 있다.)에 따라 결과값이 달라질 수 있고, 이는 시스템의 신뢰도를 떨어트린다. 이러한 문제를 해결하기 위해 하나의 프로세스가 공유 자원에 접근하는 동안 다른 프로세스의 접근을 막는, 이른바 상호 배제에 대한 노력이 이루어져 왔다.
다음은 상호 배제를 위한 요구 조건이다.
1. 임계 자원 또는 임계 영역(critical section)에 대한 접근은 한 순간에 반드시 하나의 프로세스에게만 허용되어야 한다. (상호 배제)
- 임계 자원, 임계 영역 : 두 개 이상의 프로세스가 동시에 사용할 수 없는 자원(동시에 사용할 경우 문제 발생)을 임계 자원이라 하고, 임계 자원을 사용할 수 있도록 하는 코드 상의 영역을 임계 영역이라고 한다.
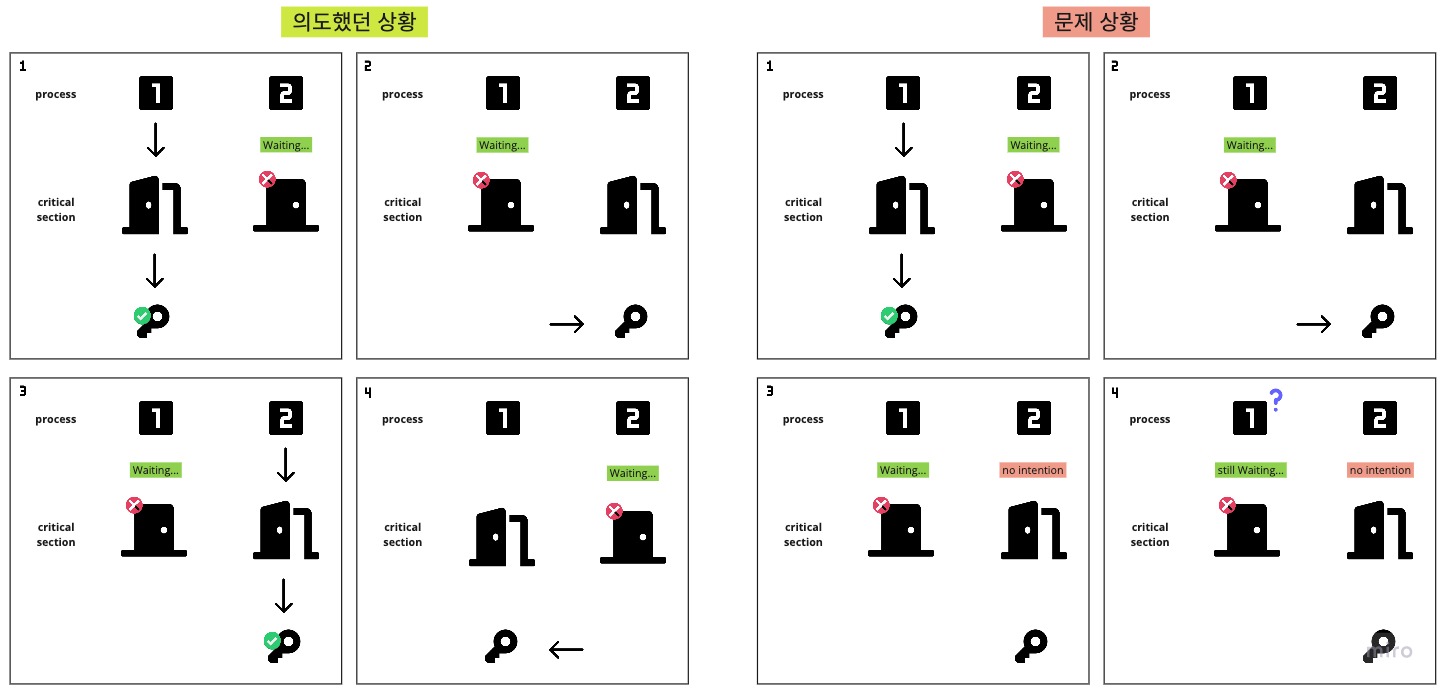
2. 임계 영역을 사용할 의향이 없는 프로세스에 의해 다른 프로세스의 수행이 간섭받아서는 안된다.
ex. 교대 진입 : 프로세스 P1의 임계 영역 실행이 끝난 후 프로세스 P0의 실행 순서가 오도록 설계할 경우, P0은 P1이 반드시 임계 영역을 실행해야만 자신의 차례를 받을 수 있다. 만약 임계 영역에 대한 P1의 실행 의사가 없는 경우 P0은 P1이 임계 영역을 실행하고 싶어 할 때까지 기다려야 하고 P1의 임계 영역 실행이 끝나야만 자신의 차례를 받을 수 있다.
즉, 임계 영역에 진입한 프로세스가 없음에도 불구하고 다른 프로세스에 의해 임계 영역에 대한 진입이 제한되는 경우를 말한다. 기타 다른 이유로라도 프로세스 간 간섭이 발생해서는 안된다.
3. 교착 상태(deadlock)나 기아(starvation)가 발생하지 않아야 한다.
- 교착 상태 : 상호 배제가 이루어지고 있는 상황에서 두 프로세스가 서로 상대방이 사용 중인 자원을 요구하며 계속 대기만 하는 상황. 어느 프로세스도 수행을 이어나갈 수 없다.
- 기아 : "특정" 프로세스가 오랫동안 자원을 사용하지 못해 실행되지 못하고 있는 상태.
프로세스 수행 순서가 골고루 배분되지 않아 특정 프로세스가 소외되는 것. (교착 상태 X)
4. 알고리즘 설계 시, 프로세서의 개수나 상대적인 수행 속도에 대한 가정이 없어야 한다.
5. 임계 영역에 들어간 프로세스는 그 안에서 무한정 있을 수 없다. (일정한 시간 내에 임계 영역에서 나와야 한다.)
이후부터는 Dekker와 Peterson의 알고리즘을 보면서, 각각의 알고리즘이 위 요구조건을 만족하는지 확인할 것이다.
이 중 알고리즘 적용 상황에 따라 달라질 수 있는 조건들은 확인할 항목에서 제외시켰다.
Dekker's Algorithm
dekker의 알고리즘은 2개의 프로세스 간 상호 배제를 위한 알고리즘이다.
또한 flag[2]와 turn이라는 두 개의 공유 변수를 사용하는데, 각각의 용도는 다음과 같다.
- flag[2] : 각 인덱스 번호에 해당하는 프로세스가 자신의 임계 영역 사용 의사 표시 (true : 원함, false : 원하지 않음)
- turn : 어떤 프로세스에게 임계 영역 진입에 대한 우선권을 줄지 표시 (0 : P0 차례, 1 : P1 차례)
이들을 사용하여 구현된 알고리즘은 다음과 같다. (P0은 process 0을 의미하고 P1은 process 1을 의미한다.)
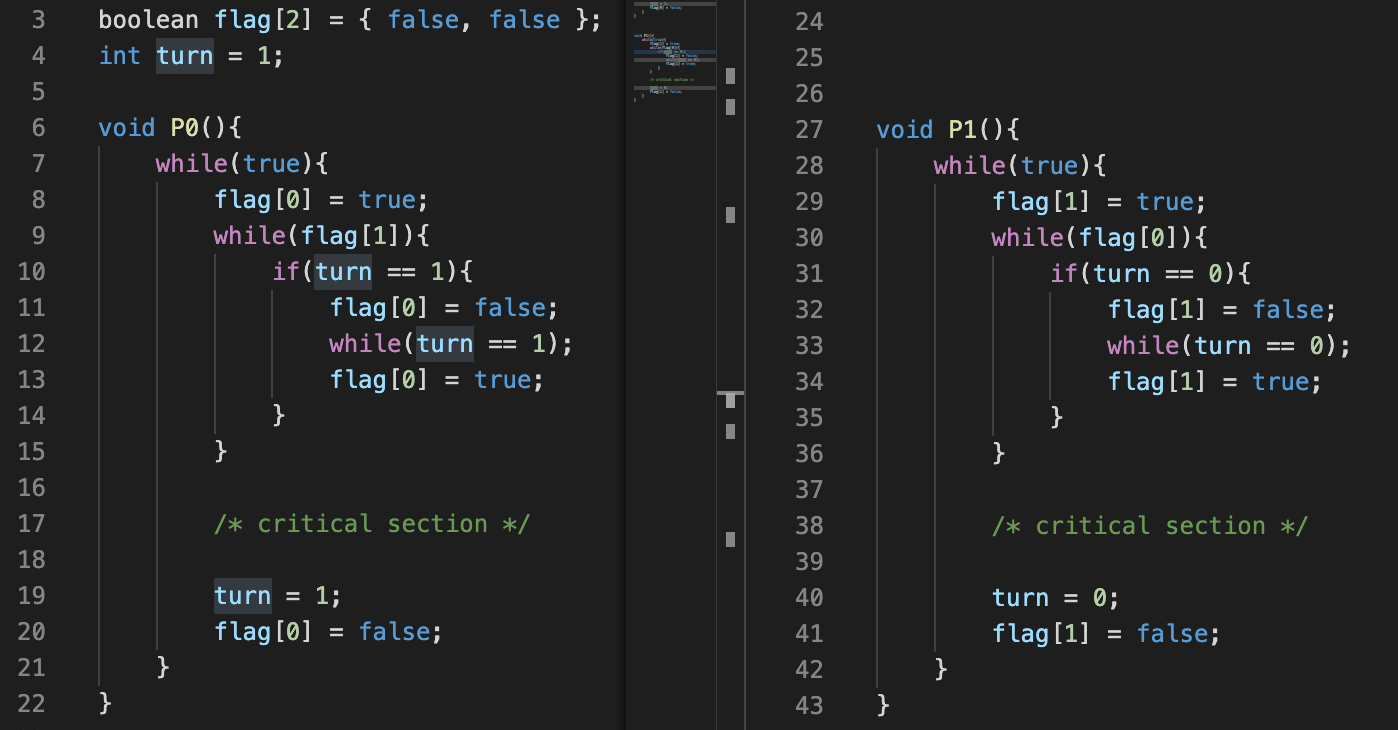
이 알고리즘은 다음의 과정으로 수행된다.
- 자신의 flag를 true로 설정한다. (사용 의사 밝힘)
- 상대편 flag을 확인하고, 상대편이 임계 영역 사용 의사를 보일 경우 turn 값을 확인한다.
2-1. 상대편이 실행될 차례일 경우 자신의 사용 의사를 잠시 false로 설정해둔다. (상대편에게 양보)
2-2. 상대편의 임계 영역 사용이 끝날 때까지 대기(while)한다.
2-3. 사용이 끝난 뒤 다시 사용 의사를 true로 설정한다. - 상대편이 사용 의사를 보이지만 turn 값이 자신의 차례를 가리킬 경우, 양보하지 않고 상대편이 양보할 때까지 기다린다.
- 상대편이 자신의 사용 의사를 false로 설정할 경우(양보해줄 경우) 임계 영역(critical section)에 진입할 수 있다.
- 임계 영역 실행 후 차례를 상대편으로 넘기고, 자신의 사용 의사를 false로 설정한다.
요구 조건 만족도 체크
1. 상호 배제가 지켜지는지 : O
-> 하나의 프로세스가 임계 영역에 진입한 경우 이 프로세스가 임계 영역을 빠져나와 turn값과 flag를 바꿔주지 않는 한 다른 프로세스가 임계 영역에 접근할 수 없다. 또한 두 프로세스가 모두 임계 영역에 진입하기 전 경쟁 상태일 때, 1 또는 0의 상태만 가질 수 있는 turn값을 확인하는 것에 의해 둘 중 하나의 프로세스만 임계 영역으로 진입할 수 있게 된다.
2. 교대 진입이 필요 없는지 : O
-> while(flag [상대])에 의해 상대편이 임계 영역에 진입할 의사가 없다면 turn값에 관계없이 임계 영역에 진입할 수 있다.
3. deadlock이 일어나지 않는지 : O
-> 상대편이 사용 의사를 밝힌다고 무조건 양보하는 게 아니라, if(turn ==?)에 의해 차례를 확인하면서 한 번에 하나의 프로세스만 양보하도록 한다. 따라서 동시에 두 프로세스가 서로의 양보를 기다리는 deadlock은 발생하지 않는다.
3-1. livelock이 일어나지 않는지 : O
-> deadlock에 걸리면 두 프로세스가 그대로 멈춰버리는 것을 떠올리면 된다. 그러나 livelock은 프로세스가 작업을 계속 하기는 하지만, 상대방이 자원을 줄 때까지 일정 루틴을 무한히 반복하며 무의미한 코드만 실행하는 식으로 lock이 걸리는 것을 말한다. 현재 코드에서는 상대 프로세스가 자원 사용을 양보할 때까지 계속 반복문을 돌기는 하지만 그 안에서 무의미하게 상태를 변경하는 것과 같은 작업은 하지 않는다. 또한 3번의 이유와 마찬가지로 한 번에 하나의 프로세스만 양보하도록 하기 때문에 서로의 양보를 기다릴 필요도 없게 된다.
4. 프로세서의 개수나 속도에 대한 가정이 없는지 : X
-> 위 알고리즘은 프로세서가 2개인 상황을 가정하고 작성된 알고리즘으로, 3개 이상인 경우에 대해서도 적용되는지는 확인할 수 없다.
Peterson's Algorithm
peterson의 알고리즘도 dekker의 알고리즘과 마찬가지로 2개의 프로세스 간의 상호 배제만을 가정하고 만들어진 알고리즘이다.
또한 dekker와 마찬가지로 flag[2]와 turn이라는 공유 변수를 사용하며, 각각의 용도는 dekker와 동일하므로 생략한다.
이를 사용하여 만들어진 알고리즘은 다음과 같다.
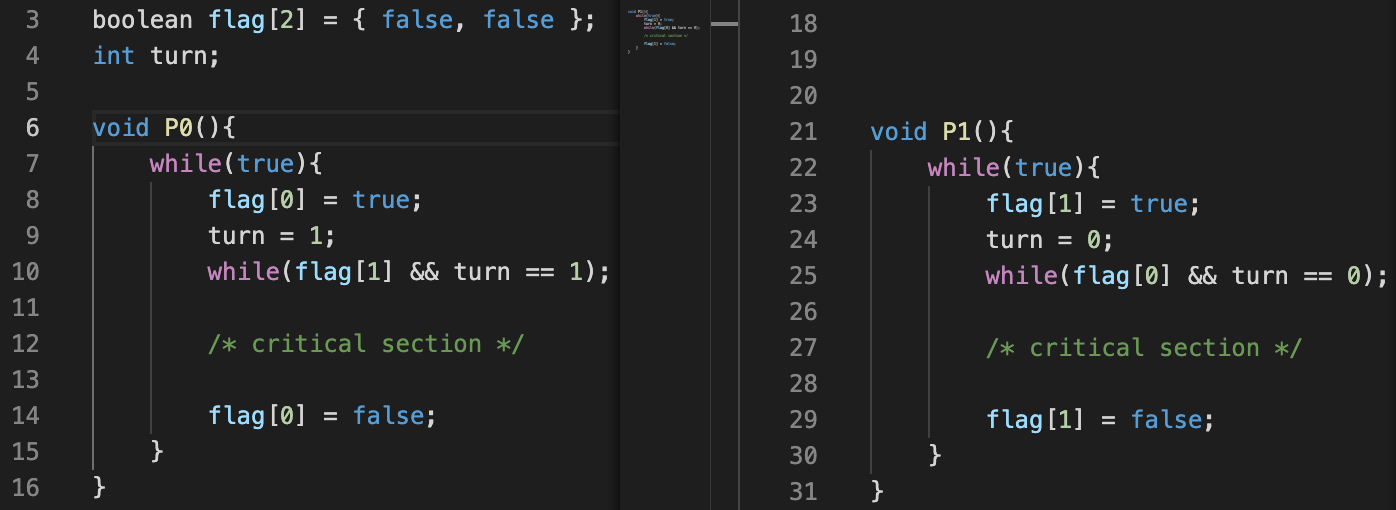
이 알고리즘은 다음의 과정으로 수행된다.
- 자신의 flag를 true로 설정한다. (사용 의사 밝힘)
- turn값을 일단 상대방의 차례로 설정한다.
- 상대방 차례에 상대방의 사용 의사가 있을 경우 대기한다.
- 상대방의 임계 영역 사용 의사가 없거나, 자신에게로 차례가 있을 경우 임계 영역에 진입할 수 있다.
- 임계 영역의 실행이 끝난 후 자신의 사용 의사를 false로 설정한다.
요구 조건 만족도 체크
1. 상호 배제가 지켜지는지 : O
-> 상호 배제를 지키기 위해서는 결국 임계 영역에 한 번에 하나의 프로세스만 진입하도록 하면 된다. 따라서 임계 영역에 진입한 프로세스가 없는 상황이라면 언제 들어가든 상관이 없다. 이를 고려한다면 프로세스는 상대방의 사용 의사가 있을 때에만 turn값을 확인하여 차례를 기다리면 된다. 여기서 차례를 나타내는 turn값은 한 번에 0 또는 1의 값만 가질 수 있기 때문에 상호 배제 조건을 만족한다.
2. 교대 진입이 필요 없는지 : O
-> 자신의 차례가 아니더라도 상대방이 임계 영역에 진입할 의사가 없으면 언제든 임계 영역에 진입할 수 있다.
3. deadlock이 일어나지 않는지 : O
-> 어떤 코드의 실행이 먼저 일어나든 turn값에는 0 또는 1만 들어갈 수 있다. 따라서 두 프로세스가 동시에 서로의 자원을 요구할 일이 없어 deadlock이 일어나지 않는다.
3-1. livelock이 일어나지 않는지 : O
-> 반복문 안에서 상태(flag나 turn) 변경 작업을 하지 않는다. (while(true)는 대기를 위한 반복문이라기보다 프로세스가 수행할 다른 작업들을 가리킨다. 실제 알고리즘 상으로 반복을 하도록 의도한 게 아니라는 의미.)
4. 프로세서의 개수나 속도에 대한 가정이 없는지 : X
-> dekker의 알고리즘과 마찬가지로 2개의 프로세스에 대한 알고리즘이므로, 3개 이상의 프로세스에 대해서도 적용되는지는 별도로 확인해봐야 한다.
요구 조건 체크만 보더라도 Dekker의 알고리즘을 보완한 것이 Peterson의 알고리즘인 것을 알 수 있다.
문제는 두 알고리즘이 매우 비슷해 보여서 어떤 차이인지 헷갈린다는 것이다.
따라서 두 알고리즘의 차이점만 정리해본다면, Dekker의 알고리즘은 임계 영역을 실행한 후 turn값을 상대방에게 넘겨주고 Peterson의 알고리즘은 아예 조건 체크를 하기 이전에 turn값을 상대방에게 먼저 넘겨주고 시작한다.
위 두 알고리즘은 각종 요구 조건을 만족시키면서 소프트웨어적으로 상호 배제를 구현한 알고리즘이라고 볼 수 있다. 그러나, 2개의 프로세스를 가정하고 구현한 것이기 때문에 자체로는 한계점이 있다. 이를 해결하기 위해 하드웨어적인 방법, 운영체제와 프로그래밍 언어 수준에서 지원하는 상호 배제 방법 등을 사용할 수 있다.
'Algorithm' 카테고리의 다른 글
| Tim sort 알고리즘 (2) | 2023.02.04 |
|---|