이 글은 2021년 11월, Windows 10 Chrome Disk Cache ver 2.0을 기준으로 한 분석 내용임을 밝히고 시작한다.
Chromium Project disk cache 문서의 내용을 바탕으로 분석을 시작하였는데, 실제 로컬에 저장된 내용과 차이가 있는 부분이 있어서 그러한 내용을 중심으로 글을 작성하였다.
Cache Directory 경로
C:\Users\<username>\AppData\Local\Google\Chrome\User Data\Default\Cache
Disk Cache 구조
Chrome에서는 각 캐시 데이터를 entry 단위로 저장한다.
disk cache에 저장되는 모든 데이터는 그것이 저장되어 있는 위치를 가리키는 cache address를 가지고 있다.
앞서 캐시 데이터 저장에 사용된다고 했던 entry 역시 그러한 cache address를 가지고 있다.
이 정도의 정보를 가지고 아래의 구조도를 보도록 하자.

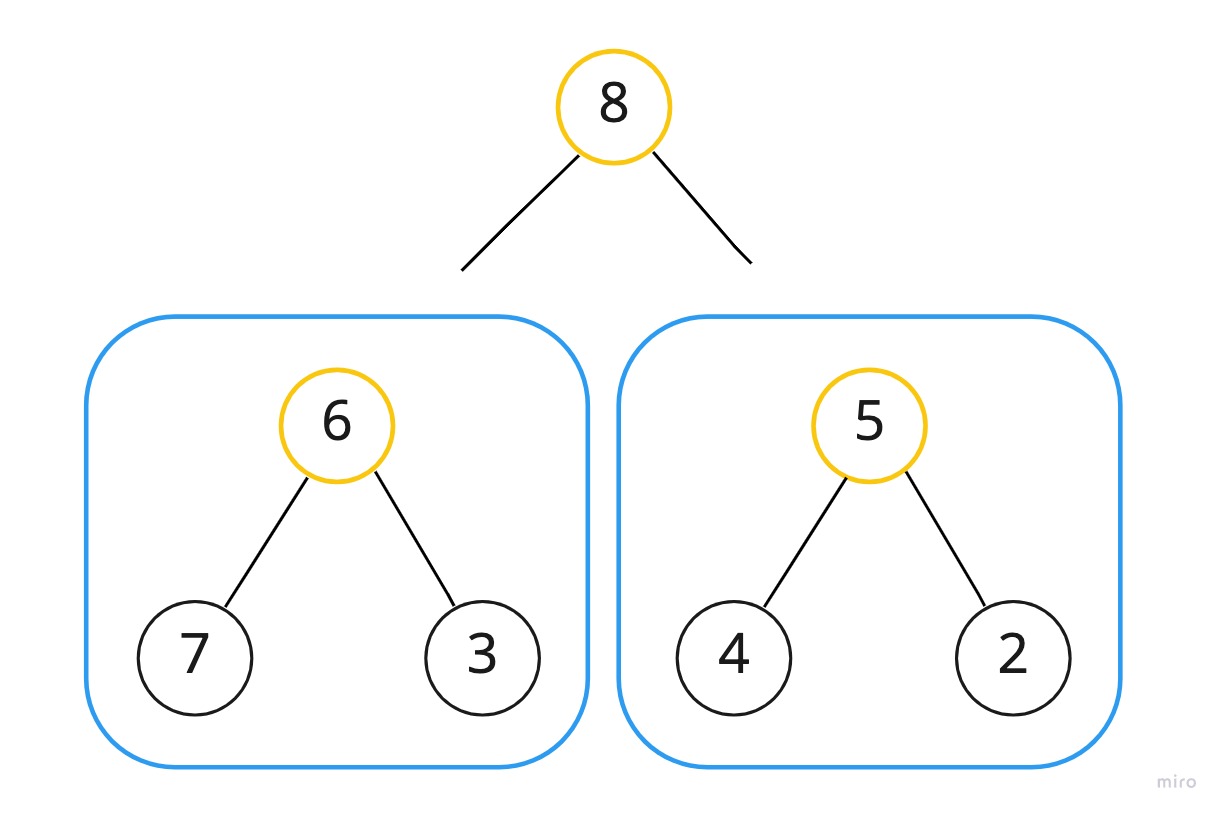
Chromium design document disk_cache 문서에 의하면 disk_cache는 다음의 세 가지 유형에 해당되는 파일로 이루어져 있다.
- index : 캐시 데이터 추적의 시작.
캐시 데이터가 다운로드된 url의 해시값을 키로 하고 그에 대응되는 값으로 entry의 cache address를 가지는 해시 테이블이 저장된 파일. header가 존재한다(그림 1).
- data_x (block file) : 리소스 데이터가 저장된 파일.
HTTP header부터 시작해서 실제 캐시의 raw 데이터까지 저장되어 있다. header가 존재한다(그림 2).
각 파일별로 주로 저장되는 데이터의 유형이 다르다.. (ex. data_1 에는 entry가 저장된다.)
- f_0000xx (separate file) : 크기가 큰 캐시 데이터를 저장하는 파일.
캐시 데이터가 kMaxBlockSize 보다 클 경우 block file 내에 저장되지 못하고 별도의 파일에 저장된다. (kMaxBlockSize = 16KB)
separate file은 index, block file과 달리 파일 자체의 헤더가 존재하지 않고 오로지 캐시의 raw 데이터만 저장된다.
- 참고: block file의 body내용은 offset 0x2000부터 있다.
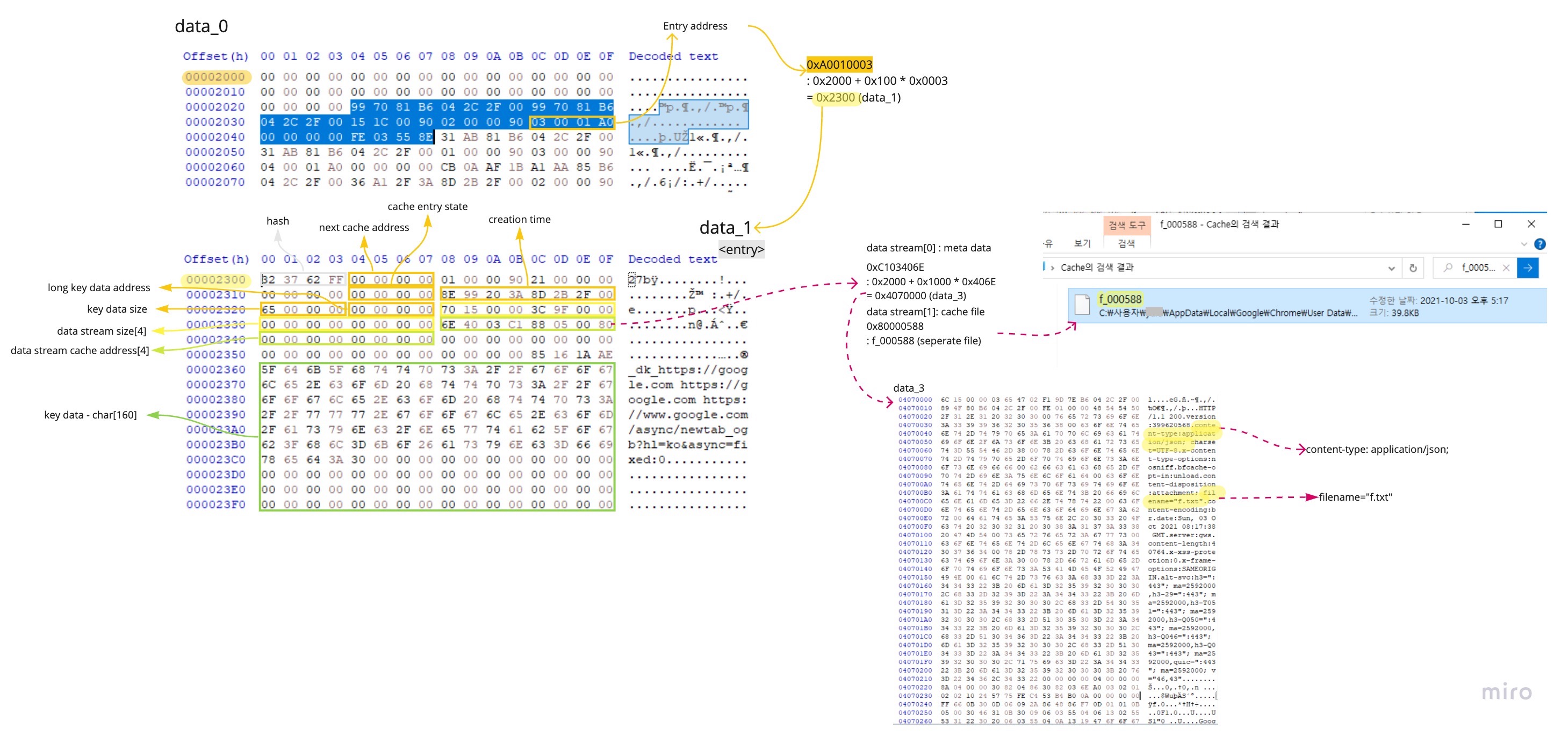
이 내용을 바탕으로 실제 내 컴퓨터 환경의 disk cache를 분석하였는데, index file에서 해결되어야 할 entry의 cache address가 data_0 file에 담겨있었다. 아래 (그림 3)에서도 볼 수 있다시피 해시 테이블이 시작되어야 할 위치인 0x160 이후로 데이터가 매우 드물게 존재하고 있다. 반면에 data_0 파일에서는 0x24 bit 단위로 캐시 데이터가 저장되어 있으며 이 중 빨간색으로 표시된 부분이 entry address이다.
이밖에도 11월 14일 기준으로 확인해봤을 때 data_0 파일과 달리 index 파일은 여전히 마지막 수정일이 10월 29일에 멈춰있다.
이러한 정황들을 통해 index 파일보다는 data_0 파일의 entry address가 더 신뢰성 있다고 판단하여 이를 가지고 분석을 이어나갔다.
Cache Address 읽는 법
Chromium disk cache 문서에 의하면 cache address는 크게 3가지 유형으로 나뉜다.
- 0x00000000 : 정의되지 않음
- 0x8000002A : separate file (file name: f_00002A)
- 0xA0010003 : data_1 block file의 0x0003번째 block
정의되지 않은 경우와 separate file 의 경우는 이 정보만을 가지고 데이터를 찾아갈 수 있다.
하지만 block file에 저장된 데이터의 경우 이 정보만으로는 실제 위치를 알아내기가 어렵다..
그래서 추가적으로 조사한 결과 아래와 같은 규칙을 찾았다.
data_1에 저장된 경우 : 0xA0010003
-> 0x0003 * 0x100 + 0x2000 = 0x2300 (data_1 file)
data_2에 저장된 경우 : 0xA0020004
-> 0x0004 * 0x400 + 0x2000 = 0x3000 (data_2 file)
data_3에 저장된 경우 : 0xA0030005
-> 0x0005 * 0x1000 + 0x2000 = 0x7000 (data_3 file)
cache address로부터 해당 주소가 어느 파일에 저장된 경우인지를 얻은 후,
block number와 각 파일별로 가지는 block size를 곱해주고 파일 body의 시작 offset인 0x2000을 더하면 해당 데이터의 진짜 offset을 얻을 수 있다.
여기서 block size는 각 block file header의 entry_size 필드의 값으로부터 얻을 수 있다.
(data_1 : 0x100, data_2 : 0x400, data_3 : 0x1000)
이러한 정보를 이용하여 cache address를 따라가 보면 다음과 같이 entry를 만날 수 있다.

Chromium 문서에 의하면 하나의 entry에 data stream이 4개까지 존재할 수 있다고 하는데, 이렇게만 들으면 잘 와닿지 않는다.
그래서 직접 각각의 data stream cache address를 따라가보면 또 하나의 규칙을 발견할 수 있다.
1. data stream[0] 에는 주로 meta data 가 저장된다. 그 캐시가 저장된 http header가 저장되어 있고 이곳에서 content-type, filename 등의 정보를 얻을 수 있다. 이 meta data를 가리키는 cache address는 C로 시작된다는 것 외에는 이전에 봤던 유형과 크게 다르지 않다.
0xC103406E : data_3 block file의 0x406E번째 block
-> 0x406E * 0x1000 + 0x2000 = 0x4070000 (data_3 file)
2. data stream [1] 이후에는 주로 캐시 데이터가 저장된다. separate file을 가리키는 주소일 수도 있고, block file 내에 저장된 데이터를 가리키는 주소일 수도 있다.
이렇게 하나하나 따라가다 보면 아래와 같은 흐름으로 캐시 데이터를 얻을 수 있게 된다.
참고 자료
- Chromium disk cache docs
https://www.chromium.org/developers/design-documents/network-stack/disk-cache
- Chromium disk cache v3 docs
https://www.chromium.org/developers/design-documents/network-stack/disk-cache/disk-cache-v3
- Chromium disk cache, disk_format.h
https://chromium.googlesource.com/chromium/src/net/+/15905ac8d688a9910055170314839dc7dc7b2f75/disk_cache/disk_format.h
'DFIR > Forensic Artifacts' 카테고리의 다른 글
| Windows Registry 개요 및 주요 아티팩트 정리 (0) | 2023.07.09 |
|---|---|
| Windows Registry Timezone과 SYSTEM Control registry 백업 원리 분석 (0) | 2023.06.30 |
| SQLite record 삭제 체계 분석과 record 복구까지... 하려다 안티포렌식까지 접하게 된 일 (0) | 2022.01.04 |
| SQLite File Structure 분석 (0) | 2022.01.03 |
| [Storage] 하드디스크 구조 (0) | 2021.08.11 |