문제를 읽어보면 포트 스캔 방식의 종류로 6가지가 있음을 알 수 있는데, 각각의 유형이 가리키는 스캔 방식은 다음과 같다.
1. TCP SYN scan (half-open scan) 로그가 남지 않도록 할 때 쓰는 스텔스 스캔 방식 중 하나이다. TCP 핸드셰이킹 과정의 첫번째 단계인 SYN 패킷만 보낸 다음 이에 대한 ACK 패킷을 받는다. 대신 TCP connection이 확립되면 안되기 때문에 포트가 열려있다고 판단될 경우 RST 패킷을 보내고, 닫혀있다고 판단될 경우 응답하지 않고 멈춘다.
2. TCP ACK scan ACK 패킷만 먼저 보내고 이에 대한 응답 패킷을 검사하는 방식이다. 포트 스캔을 위한 것이 아닌 방화벽에 대한 검사를 진행하기 위한 방식이다. ACK 패킷에 대한 응답으로 RST 패킷을 받는 경우 방화벽에 의한 필터링이 되지 않고 있는 것을 판단할 수 있고, 응답이 없거나 ICMP 메세지를 받게 될 경우 방화벽에 의한 필터링이 수행되고 있다고 판단할 수 있다.
3. UDP scan UDP 프로토콜의 전송 방식과 같이 핸드셰이킹 과정을 사용하지 않는다. 대신 닫힌 포트로 UDP 패킷을 보냈을 때 서버로부터 ICMP 메세지를 받고, 열린 포트로 보냈을 경우에는 응답이 없다는 것을 이용한다. 결론적으로 UDP 패킷을 보내고 서버로부터 응답이 없을 경우 열린 포트, ICMP 메세지를 받을 경우에는 닫힌 포트라고 인식한다.
4. TCP Connect scan 일반적으로 TCP Connection을 확립할 때 일어나는 3-Way 핸드셰이킹 과정을 거친다. 그 후 정상적으로 핸드셰이킹이 완료되었다면 포트가 열려있는 것으로 판단하고, 그렇지 않으면 닫혀있는 것으로 판단한다.
5. TCP Xmas scan TCP SYN scan 방식과 함께, 로그가 남지 않도록 할 때 쓰는 스텔스 스캔 방식 중 하나이다. 동시에 여러 플래그가 설정된 패킷을 보내서 응답이 없을 경우 열려있다고 판단하고, RST 패킷이 올 경우 닫혀있다고 판단한다. 물론 응답이 없을 경우 무조건 포트가 열려있는 것이 아닌 방화벽에 의해 필터링되어졌을 수 있다.
6. TCP RST scan 이건 뭔지 모르겠다...
이 내용을 바탕으로 문제 파일을 살펴보면.. 첫 번째로 수행한 포트 스캔 방식을 찾기 위해 맨 처음에 등장한 TCP 핸드셰이킹 과정을 살펴봤다.
호스트 IP가 10.42.42.253이라는 것을 참고하면, 여기서 제일 처음으로 포트 스캔을 한 곳의 목적지 IP는 10.42.42.50이고, 80번 포트에 대한 포트 스캔이 진행됐다.
이 패킷의 tcp stream을 따라가보면 SYN - RST/ACK, 이렇게 두 개의 패킷이 송수신되고 있는 것을 볼 수 있는데, 이는 TCP Connect 스캔 방식을 사용했을 때 닫힌 포트임을 판단할 수 있는 모습이다.
Ann이 클릭한 첫 영화의 제목을 구해야 한다. pcap 파일로 주어진 문제 파일을 확인하기 위해 Wireshark를 실행시켰다.
우선 주어진 패킷 파일 중 Ann이 사용한 IP주소에 해당하는 패킷만 보기 위해 필터 조건을 설정했다. 글자가 작아서 잘 안보이겠지만 ip.addr==192.168.1.10 이라고 입력한 상태이다.
필터링을 했지만 여전히 패킷이 많아서 쉽게 찾기에는 어려움이 있어 보인다.
힌트를 얻기 위해 문제를 다시 읽어보면, 구해야 하는 것은 Ann이 클릭한첫영화의 제목이다.
Ann이 클릭 이벤트를 발생시킨 것에 의해 서버에 request 패킷이 보내졌을 것임을 짐작하고, [Statistics] - [HTTP] - [Requests] 메뉴에 들어가서 관련 패킷이 있는지 확인한다. 물론 여기서 관련 패킷이라는 것은 영화와 관련된 패킷을 말한다.
해당 메뉴에 들어가면 아래와 같이 현재 패킷 목록에서 사용된 request 주소들을 확인할 수 있는데, 영화를 클릭했다는 것은 클릭을 통해서 그 영화를 볼려고 했을 것이라고 자연스레..? 생각할 수 있다. 사실 너무 자연스럽게 viewMovie 라는 키워드가 눈에 띄어서 여기에서 사용된 id값을 wireshark packet 목록에서 검색했다. 이 id값이 사용된 위치와 인접한 곳에 해당 id값을 가지는 영화의 정보도 함께 있으리라 생각했기 때문이다.
이 Requests 목록에서는 viewMoview 키워드를 가지는 url이 두 개다. 어느 것이 먼저인지 알아보기 위해서 두 개의 id값을 모두 검색해서 packet list 상에서 먼저 나온 패킷이 어느 것인지 확인했다.
확인한 결과 id 283963264 가 있는 packet number는 883이고,
id 333441649 가 있는 packet number는 56이다.
더 빨리 발생한 request가 56번 패킷이므로 이 패킷의 데이터를 확인했다.
그리고 예상대로 이 id값이 위치한 곳에서 인접한 위치에 title이라고 적힌 key값과 함께 Hackers라는 영화 제목을 확인할 수 있었다.
주어진 pcap 파일을 Wireshark를 이용해서 열어보면 가장 먼저 보이는 packet list에서 눈에 띄는 프로토콜을 발견할 수 있다.
RTP 프로토콜... Real-time Transfer Protocol의 앞글자를 딴 이름을 가지는 프로토콜로, 말 그대로 실시간 전송(스트리밍 미디어, 시스템 등)에 쓰이는 프로토콜이다.
UDP 프로토콜을 기반으로 동작하는 프로토콜이며, 그렇기 때문에 오류 검사와 수정보다는 실시간으로 데이터를 전송하는 데에 초점이 맞춰져 있다. (포트도 UDP 포트를 사용한다.)
RTP 프로토콜은 RTCP 프로토콜과 함께 쓰인다. RTCP 프로토콜이라는 이름은 Real-time Transfer Control Protocol 의 앞글자를 딴 것이며, 여기서도 짐작할 수 있듯이 RTP 프로토콜의 control을 위해 쓰이는 프로토콜이다. 이 문제에서 주어진 pcap 파일에서도 볼 수 있다시피, RTP 프로토콜을 이용하여 실시간으로 데이터를 전송할 때 중간중간 RTCP 프로토콜이 보내지고 있는 것을 볼 수 있다.
RTCP 프로토콜을 사용하는 이유로는 RTP 프로토콜의 전송 통계나 QoS(Quality of Service) 모니터링, 다중 스트림 동기화 등이 있다. 쉽게 생각하면 RTP 프로토콜의 제어 정보 및 QoS 정보, 통계 등을 전송하기 위함이라고 볼 수 있다.
hex dump를 보는게 습관이 되어서 그런지 이 문제를 본 뒤에도 RTP Header format부터 찾은 뒤에 packet hex를 들여다보았던것 같다. RTP 패킷 파일을 선택한 후 해당 패킷의 detail 페이지를 확인해보면 Payload type으로부터 전송된 데이터가 G.711 PCMA으로 된 것임을 알 수 있었다. 여기서 G.711는 주로 전화에서 사용되는 Audio 코덱인데, 이러한 정보를 참고한다면 음성 전화 내용에서 Gregory를 죽인 사람에 대한 힌트를 얻을 수 있지 않을까..
그럼 이 Audio 데이터를 어떻게 해야 들어볼 수 있을까,,
Wireshark에 내장된 기능인 RTP Player를 이용하면 된다. 이 기능을 이용하면 RTP 프로토콜의 stream만 똑 떼어내서 그 스트림으로 전송된 음성본을 들을 수 있다.
물론.. 지원되는 음성 코덱만 가능하다. 현재 내 wireshark 버전에서 지원하는 코덱이 어떤게 있는지 확인하기 위해 [About Wireshark] - [Plugins] 메뉴에 들어간다. 그리고 우측 상단부에 위치한 Filter by type에서 codec을 선택하면 아래 리스트에서 지원되는 코덱의 이름을 확인할 수 있다.
리스트를 확인해보면 제일 위에 G.711 코덱이 지원된다고 있음을 알 수 있다. 이렇게 RTP Player가 지원되는 코덱의 데이터가 전송된 것을 확인했으므로 RTP Player를 사용하여 데이터의 내용을 확인하면 될 것 같다. 이를 위해 RTP 패킷 하나를 선택한 후 [Telephony] - [RTP] - [Stream Analysis] 메뉴를 선택하여 해당 스트림을 타고 간다.
RTP Streams를 선택하면 정말 여기에 있는 RTP stream만을 리스트 형태로 보여주는데, Stream Analysis를 선택하면 stream내의 패킷들을 analysis까지 해주기 때문에 이 스트림에서 전송된 데이터를 음성 재생하여 들을 수 있게 해 준다.
[Stream Analysis] 메뉴를 선택하면 나오는 화면이다. 그리고 여기에서 아래 Play Stream 버튼을 누르면 RTP Player가 나오고, 이를 이용하여 RTP 프로토콜로 전송된 음성 데이터를 들어볼 수 있다.
Player 창을 열고 재생시키면 Jack와 Victoria가 전화를 하는 내용을 들을 수 있다. 음성이 깨끗하지는 않지만.. Jack이 Victoria에게 너가 죽였냐고 하는 것만은 분명히 들을 수 있어서 Victoria가 범인임을 유추할 수 있다.
key값을 찾기 위해 문제에서 제공한 정보는 오로지 pcapng 형식의 파일 하나뿐이었다.
Wireshark를 이용하여 열어보니 USB protocol로 통신한 흔적뿐이었다.
USB protocol에서 사용되는 통신의 유형은 총 4가지가 있는데 각 통신이 주로 사용되는 상황은 다음과 같다. 1. Control Transfer : 호스트가 장치에 명령을 전송하거나, 장치 설정 정보 등을 요청할 때 사용된다. ex) 장치 초기 설정, 관리 2. Interrupt Transfer : 소량의 데이터를 자주 보내야 할 때 사용된다. ex) 마우스, 키보드 3. Bulk Transfer : 대용량 데이터 전송에 사용된다. ex) 프린트, 대용량 데이터 4. Isochronous Transfer : 데이터의 실시간 전송에 사용된다. ex) 음악, 동영상 스트리밍
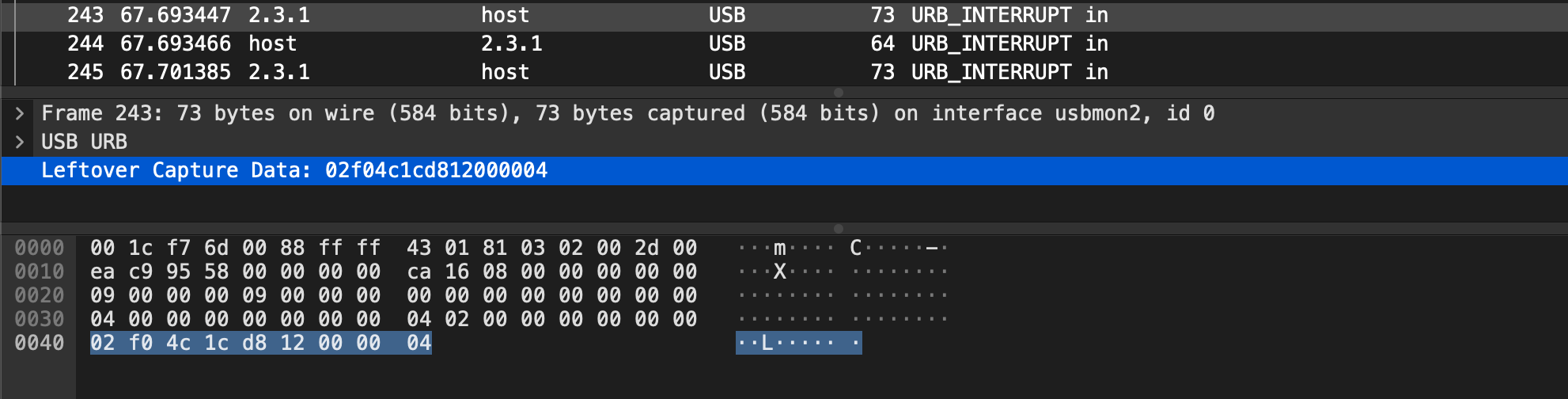
위 Wireshark 패킷 목록을 보면 알 수 있겠지만 장치가 호스트에게 interrupt 통신으로 데이터들을 계속 보내고 있다. 그리고 여기서 장치가 호스트에게 보내는 패킷들을 확인해보면, 아래와 같이 Leftover Capture Data라는 이름으로 어떤 데이터가 함께 전송되고 있는 것을 확인할 수 있다.
같은 USB protocol을 사용한다고 해도 데이터를 전송하는 형식이 다르기 때문에 어떤 장치가 보낸 데이터인지 확인할 필요가 있다.
USB 장치가 연결되면 호스트는 가장 먼저 연결된 장치에게 설정 정보를 보내라는 요청을 보낸다. (Control transfer - 1번 패킷) 이 요청을 받은 장치는 자신의 descriptor를 호스트에게 보낸다. (Control transfer - 2번 패킷) 이 과정을 통해 장치와 호스트가 데이터를 송수신할 준비를 하게 되고 그 후 통신이 시작된다. 그러므로 장치에 대한 정보는 2번 패킷인, 장치가 보낸 패킷 안에 있을 것임을 유추해볼 수 있다.
2번 패킷을 들여다보면 정말 DEVICE DESCRIPTOR가 있는 것을 볼 수 있는데, 여기서 idVendor와 idProduct를 통해 장치의 제조사와 제품명을 알 수 있다. Wacom의 Bamboo Pen인 것을 알았다. 아마 좀 전에 interrupt transfer로 전송된 많은 데이터들은 이 펜마우스로부터 전송된 데이터들인 건가 보다. (3, 4번 패킷도 마찬가지로 descriptor를 확인해보면 허브인 것을 알 수 있는데, 이후 패킷들로는 Pen과 호스트 간에 송수신한 패킷만 존재하므로 패스했다.)
그럼 이제 이 제품의 데이터 전송 형식을 찾은 뒤 capture data만 추출하여 그 데이터들이 그리고 있는 그림이 어떤 것인지 알아내면 key에 대한 정보를 볼 수 있을 것 같다.
사실 이 문제 풀면서 bamboo pen 전송 데이터 형식 찾는 게 제일 어려웠다... 일단 처음에는 bamboo pen protocol과 같은 키워드로 검색을 했는데, 여기서 발견한 것이 다음과 같은 사이트였다. bamboo pen을 판매하는 것과 같은 느낌의 사이트였는데, tech specs에서 이 펜이 microsoft pen protocol을 사용한다는 정보를 얻게 되었다. 곧바로 키워드를 바꿨다.
Microsoft Pen Protocol을 검색해보면 아래와 같은 내용이 담긴 문서를 찾을 수 있다.
문제에서 사용된 장치는 Pen.. 따라서 마우스 부분에 해당되는 부분을 보면 X좌표와 Y좌표 순서로 데이터를 전송한다는 것을 알 수 있다. 그런데 위 내용의 마지막을 보면 알 수 있지만.. Note... "however this interface would not be acceptable for a Boot Device (use separate interfaces for keyboards and mouse devices)" 대략 위의 폼으로 전송되지만 이게 확실한지를 결정하려면 추가적인 정보가 필요하다.
내가 능력이 안 되는 건지.. 정확히 저 모델의 포맷을 찾는데 실패했다,, 그래서 도움을 좀 받은 결과 다음과 같은 포멧을 가진다고 한다. 길이가 9인 Capture Data가 02 F0 4C 1C D8 12 00 00 04의 값을 가진다고 할 때,
02 F0 : 헤더 4C 1C : X 좌표 D8 12 : Y 좌표 00 00 : Z 좌표 (펜을 누른 정도, 압력) 04 : 접미사
따라서 위 패킷 목록에서 Capture Data가 있는 패킷들만 뽑은 후 그 안에서 다시 Capture Data 값만 추출해 낸다. 그 후 다시 여기에서 뽑아낼 수 있는 X 좌표와 Y 좌표를 화면 상에 나타내면 저 펜을 이용하여 어떤 그림을 그렸는지 알아낼 수 있을 것이다.
이 작업을 위해 우선 Wireshark에서 Capture Data가 있는 패킷만 골라 별도의 pcapng 파일로 저장한다. 필터링을 할 수 있는 입력란에 usb protocol packet 중 capdata가 있는 파일만 골라낼 수 있는 검색어인 usb.capdata를 입력하면 된다. 그 후 [File] - [Export Specified Packets]를 이용하여 필터링된 패킷들을 별도의 pcapng 파일로 저장한다.
그 후 패킷 내의 특정 데이터들만 추출하기 위해 Wireshark의 자매품인 tshark를 사용한다. command line 버전 Wireshark라고 생각하면 되는데 이것의 사용을 위해 리눅스를 켠다. 그 후 아래와 같은 명령어로 좀 전에 capdata만 있는 패킷 내에서 capdata 필드만 뽑아서 capdata.txt 파일에 저장한다. (tshark를 설치한 적이 없으면 설치해야 한다.. 당연히..)
$ tshark -r (대상 pcapng 파일) -T fields -e (필드명)
** 뽑아낼 필드가 여러 개일 경우 -e (필드명 1) -e (필드명 2) -e (필드명 3)...처럼 이어서 적어주면 된다.
그러면 다음과 같이 capdata 필드 값만 파일에 저장된 것을 볼 수 있다.
여기에서 필요한 값은 X, Y, Z 값이므로 이들만 추출해주기 위해 다음의 명령어를 사용할 수 있다.
뭐지.. 하는 생각을 한동안 가지고 있다가 알게 된 것이 gnuplot에 넣을 데이터 체계가 gnuplot이 실행되고 있는 시스템의 체계와 일치하도록 해야 된다는 것이었다. 즉, 내 gnuplot이 실행되고 있는 리눅스 환경은 little endian 바이트 체계를 사용하기 때문에 내가 입력해주는 데이터도 little endian 형식으로 만들어서 넣어줘야 한다는 것이다.
http://www.gnuplot.info/docs_5.5/Gnuplot_5_5.pdf
내 데이터는 big endian 체계로 가져온 값이 었는데 이 부분 때문에 문제가 생겼나 보다... 하고 리틀 엔디안 방식으로 x, y값의 체계를 바꿔서 저장할 수 있도록 코드를 수정했다.
from pwn import *
f = open("data.txt", "r")
for s in f.readlines():
ss = s.split(" ")
x = int(ss[0], 16)
y = int(ss[1], 16)
z = int(ss[2], 16)
if z > 0:
print(u16(struct.pack(">H", x)), u16(struct.pack(">H", y)))
** u16 함수와 struct.pack 함수는 pwntools 라이브러리에서 지원하는 함수이다.
u16는 16바이트의 패킹된 바이트 문자열을 인자로 받아 unpacking 된 바이트 문자열로 바꿔주기 위해 사용된다. endian에 대한 별다른 옵션을 붙여주지 않을 경우 기본적으로 들어온 바이트 문자열을 little endian 타입으로 변환한다.
이 글은 SQLite File structure 분석에 이어지는 글이며, SQLite에서 레코드를 삭제할 경우 파일 내에 생기는 일과 그렇게 삭제된 레코드가 관리되는 방식을 다룬다.
레코드는 Leaf page에 저장되어 있다. 따라서 레코드 삭제 요청이 들어올 경우 가장 먼저 변화가 일어나는 곳도 Leaf page이다.
Page의 구조가 아래와 같다는 것을 고려할 때, Leaf page에서 어떤 레코드가 삭제되면 해당 레코드를 가리키던 cell offset의 값도 삭제될 것임을 짐작해볼 수 있다. 그렇다면 기존의 cell offset이 가리키고 있던, 삭제된 cell 공간은 추후 데이터의 삽입이 일어날 때 재사용이 될까? 효율을 위해서라면 높은 확률로 재사용될 텐데 이를 위해 어떤 체계를 쓰고 있을까?
Page structure
이러한 물음에 대한 답을 찾고자 데이터베이스 파일 내부를 직접 들여다보았다.
테스트를 위해 7개의 레코드를 갖는 테이블을 만들었다. 이 레코드들은 모두 하나의 Leaf page 안에 있는 상황이다.
현재 page header의 offset 0x3에 위치한 number of records의 값은 7이며, 7개의 레코드는 첫번째부터 순서대로 다음의 offset을 갖고 있다. -> 0xFEC, 0xFD7, 0xFC2, 0xFAD, 0xF98, 0xF83, 0xF6E
이 상태에서 제일 마지막 offset인 0xFEC에 위치한 순서상으로는 첫번째 레코드(aa..)를 삭제해보았다.
page의 처음으로부터 offset 0x08에 위치했던 0xFEC가 사라지고, 그 자리를 이후에 위치한 offset값들이 차지하고 있는 것을 알 수 있다. 이와 함께 number of records 값이 6으로 변했다.
여기서 cell offset 배열 내의 한 원소를 삭제할 때 그 이후의 값들을 하나씩 당겨오는 방식으로 원소를 삭제한다는 것을 알 수 있다.
삭제된 셀이 위치해있던 0xFEC에서 일어난 변화를 보면, 첫 4 바이트가 4바이트의 어떤 정수로 덮어씌워졌으며 그 이후의 데이터는 여전히 파일에 남아있는 것을 볼 수 있다. 이 덮어씌운 정수가 어떤 값을 의미하는지를 확실히 하기 위해 이번에는 중간에 있는 데이터를 삭제해보았다.
offset 0xFC2 에 위치해있던 (초기데이터 기준으로) 세번째 레코드(cc..)를 삭제했다.
page header와 cell offset 배열에 일어난 변화는 이전과 동일했는데, 레코드의 첫 4바이트가 또 다른 어떤 정수로 바뀐 것을 볼 수 있다.
가만 보면 4 바이트 중 상위 2 바이트는 이 다음에 위치한 삭제 레코드의 offset이고, 하위 2 바이트는 이 다음에 위치한 삭제되지 않은 레코드와 현재 레코드와의 offset 차이값을 나타냄을 알 수 있다. (0x2FC2 + 0x15 = 0x2FD7이다. -> 두번째 레코드의 offset)
이러한 가정을 조금 전에 시도했던, page의 끝에 위치한 레코드를 삭제했을 경우에 적용해보면.. 이후 위치한 삭제 레코드가 없으므로 상위 2 바이트의 값이 0이었고, 이후 위치한 삭제되지 않은 레코드의 값은 이 다음 페이지와의 offset 차이값을 가지고 있었다는 것으로 그 정수값의 의미를 유추해낼 수 있다. (0x2FEC + 0x14 = 0x3000이다. -> 세번째 페이지의 offset)
여기에 SQLite에서 page간의 관계가 B+ Tree 구조로 이루어져 있다는 것까지 함께 고려한다면 위 가정에 신뢰를 더할 수 있다. (B+ Tree는 Leaf 노드끼리 연결리스트 구조를 이루고 있어 이들간의 선형 탐색이 가능하도록 되어있다.)
그렇다면 이렇게 삭제된 노드의 저장공간이 어떻게 활용되는지 확인하기 위해 새로운 레코드 하나를 추가해보겠다.
그러자 cell offset 배열의 마지막 위치에 익숙한 offset 0xFC2가 추가된 것을 확인할 수 있다. 이는 바로전에 삭제했던 레코드(cc..)의 offset이었으며, 새롭게 들어온 레코드(hh..)의 저장도 이곳에 이루어진 것을 확인할 수 있다.
삭제된 레코드의 offset은 분명 cell offset 배열에서 삭제되었는데 어떻게 이 offset을 다시 찾아갈 수 있었을까? 답은 page header의 offset 1에 위치한 offset of first block of free space 값에 있다.
눈치가 빨랐다면 이미 알았겠지만 사실 지금까지 레코드를 삭제하는 동안 이 값은 그에 따라 계속 변하고 있었다.
초기의 page header첫번째 레코드(aa..) 0xFEC를 삭제했을 때 page header세번째 레코드(cc..) 0xFC2를 삭제했을 때 page header
이는 마치 다음과 같은 연결리스트가 있을 때 가장 끝에 있는 노드, 즉 가장 빠른 offset을 가지고 있는 노드를 pointer가 가리키고 있는 구조로 생각할 수 있다. 여기서의 pointer 방식이 page header의 offset 1에 값을 저장하는 것이라고 생각하면 되는 것이다. 이 때, offset 값을 기준으로 오름차순이 되도록 새로운 노드가 추가되며 그렇기 때문에 레코드를 삭제한다고 해서 꼭 pointer의 값이 달라지는 것은 아니다. (pointer는 가장 빠른 offset의 free block을 가리키고 있기 때문.)
그러다 새로운 레코드가 추가되면 이 pointer가 가리키고 있는 offset에 해당 레코드를 저장하는 것이다.
이렇게 데이터를 삭제하고 삭제한 위치를 관리하는 시스템을 이용한다면 삭제된 데이터를 복구하는 작업도 가능하게 된다. 앞서 봤던 것처럼 연결리스트 구조를 이용하여 삭제된 데이터가 저장된 위치만을 순회할 수 있고, 데이터가 삭제된다고 하더라도 해당 레코드의 상위 4 바이트만 변경이 되지 그 이후의 데이터는 그대로 남아있기 때문이다.
그래서 원래 이 삭제 메커니즘을 분석했던 이유도 Chrome browser History를 복구해보기 위한 선행 지식이었기 때문이었는데, 알게 된 지식을 이용하여 History 데이터베이스를 따라가보니 안티포렌식 처리가 되어 있음을 확인해버렸다.. 슬픈 결과이지만 그를 따라갔던 과정이라도 적고 마무리 하려고 한다.
Chrome 96.0 기준으로 확인한 결과이며, 언제부터 이것이 적용되었는지는 모르겠지만 이전 버전에서는 다른 결과를 보일 수도 있다.
아래는 내 Chrome local에 저장된 History 데이터베이스 내에 있는 urls 테이블의 한 Leaf page를 가져온 것이다.
page header offset 1 값에 의해 마지막으로 삭제된 레코드의 offset이 0x50A임을 알 수 있다. 해당 위치로 따라가보았다.
예상했던대로 첫 4바이트는 (다음 free block의 offset 2바이트 : 다음 cell과의 offset 차이값 2바이트) 로 이루어진 값이 저장되어있다. 그런데 문제는 4바이트 이후에 저장되어 있어야할 데이터가 모조리 0으로 채워져있다는 점이다.
다음 free block의 offset인 0x1E000 + 0xC8E 로도 쫒아가 나머지도 모두 같은 상황인지 확인했다.
마찬가지였다.
이 후 다른 테이블로 넘어가 몇개의 free block을 더 확인하였는데.. 삭제된 위치의 첫 4바이트 이후 값은 모두 0으로 지워져있었다.
Chrome History 복구 모듈을 만들어보고자 하는 목적으로 시작한 공부였는데, 끝이 이렇게 날 줄은...
아쉬우니 다음에 Chrome이 아닌 다른 SQLite 데이터베이스 파일의 복구 모듈을 만들어보는 것도 도전해봐야할 것 같다.
1. Header page 1) Database header (size: 0x64) : Database에 대한 정보를 가지고 있다. - DB size, Text Encoding 방식, page size, number of pages 등
2) Schema Table : Database내에 있는 table, index 테이블에 대한 스키마 정보를 가지고 있다. - 테이블 유형(table / index), root page offset, CREATE 시 사용한 query 텍스트 - 데이터베이스 내에 있는 하나의 테이블에 대한 정보가 Schema Table의 하나의 레코드로 저장되어 있다. ** 여기 자체로 또 하나의 page 구조를 보이고 있어서, 여기의 상위를 Header page라고 표현했지만 사실상 그냥 Database file header와 Schema page가 있다고 생각하는 게 더 간편하다.
2. Interior Page, Leaf Page (B+Tree) : Schema Table에서 얻을 수 있는 root의 offset을 이용하여 각 테이블의 root page에 접근할 수 있다. 테이블 내에 저장된 레코드가 하나의 page를 넘어가지 않을 경우 단일 leaf page에 저장되고 root page offset은 이 leaf page를 가리키게 된다. 그러나 레코드의 개수가 하나의 페이지를 넘어설 경우 여러 leaf page를 통해 저장되고 이 여러 leaf page들의 offset을 포인터로 가지는 interior page의 offset이 root page offset에 저장된다.
3. Overflow Page, Free Page - Overflow Page : 데이터를 한 페이지에 전부 담을 수 없는 경우 생성되는 페이지 - Free Page : overflow page를 가지고 있던 레코드가 삭제된 경우 overflow가 free page로 전환되어 생기는 페이지
여기까지 설명한 데이터베이스 구조를 도식화시키면 다음과 같다.
이재형 외 3명, ⌜SQLite 데이터베이스 파일에 대한 데이터 은닉 및 탐지 기법 연구⌟, 『Journal of The Korea Institute of Information Security Cryptology VOL.27 NO.6』, Dec. 2017, Fig. 5
아래는 Header page에 있는 Database Header와 그 이후의 Schema Table을 가리키는 header 정보를 캡처한 것이다. header 정보를 이용하여 Schema를 찾아가는 법에 대해서는 곧바로 나올 page 구조에 대해 이해하면 알 수 있다.
Header page의 최상단 부분
위에서 page라는 용어를 계속 사용하였는데, 이는 SQLite에서 채택한 구조인 B+Tree에서의 하나의 노드라고 생각하면 된다.
데이터베이스 파일 내에서 사용되는 페이지의 유형은 Header Page를 제외하고 크게 Interior page와 Leaf page로 나눌 수 있다.
Interior page에는 Leaf page를 가리키는 cell만이 존재할 뿐 실제 DB 데이터는 모두 Leaf page에 저장되어 있다. 따라서 레코드 탐색 시 각 table의 Schema Table에 있는 root page offset에서 시작하여 Leaf page가 나올 때까지 순회한다.
Leaf page도 Interior page와 구조는 비슷하나, cell에 Leaf page의 offset이 아닌 실제 데이터베이스에 저장된 데이터가 있다. 하나의 cell에는 데이터베이스 내의 하나의 레코드에 해당하는 데이터가 있다.
이러한 Page는 다음의 구조로 구성된다.
1. Page Header (size: 0x0C - Interior / 0x08 - Leaf) : Page에 대한 정보를 가지고 있다. page의 유형에 따라 header의 크기가 달라진다. - Offset 0 : 0x05 - Interior / 0x0D - Leaf
2. Cell Offset (2 bytes array) : 배열 형태로 각 cell에 대한 offset을 저장한다. 배열에 저장된 각 offset이 가리키고 있는 cell은 페이지의 마지막부터 채워진다. page header와 cell offset이 페이지 상단부터 채워지고, cell의 데이터가 페이지의 하단부터 채워지는 구조이다. 이것에 의해 페이지의 중간에 free space가 생기게 된다.
파일 구조를 따라가다 보면 number와 offset이라는 용어를 마주하게 된다.
number는 주로 page를 찾아갈 때 사용되고, offset은 셀을 찾아갈 때 사용된다.
이 둘은 계산하는 방법이 조금 다른데,
page number로부터 파일 내에서의 page offset을 구하기 위해서는 다음의 수식이 사용된다. page offset = (page number - 1) * page size page size는 database header의 offset 0x10에 있는 2 bytes를 통해 알 수 있다.
주어진 cell offset으로부터 파일 내에서의 offset을 구하기 위해서는 다음의 수식이 사용된다. (파일) cell offset = 해당 page의 시작 offset + (주어진) cell offset
여기까지의 내용을 가지고 Header page에서부터 특정 테이블의 record에 접근하는 과정을 따라가 보면 다음과 같다.
연두색으로 형광표시해둔 곳을 대표로 따라가 보았다. 여기서는 root page로 곧바로 leaf page가 나와서 금방 record에 도달할 수 있었는데, interior page가 나오는 경우에 대해서도 보자면 다음과 같다.
마지막으로 레코드 안에 있는 각 칼럼의 데이터를 파싱 하기 위한 레코드 구조에 대해 살펴보려고 한다.
SQLite에서는 파일 용량을 절약하기 위한 방법으로 variable length integer(일명 varint)를 사용한다. 이는 1~9 byte의 크기를 가지는 가변 길이 정수를 말하는데, 각 바이트의 MSB는 다음 바이트의 유무를 나타내는 비트로 사용하고 실제 데이터는 나머지 7개의 비트에 저장한다. MSB가 1일 경우 표현하려는 정수가 7비트의 표현 범위를 넘어가 다음의 추가적인 바이트를 사용한다는 의미를 가지며, 0일 경우는 해당 바이트가 해당 필드의 마지막 바이트라는 것을 의미한다. 이러한 표현방식을 이해하기 위해 다음의 예제를 살펴보자.
ex. varint 0x8106 이 나타내는 정수는? 0x8106 = 10000001 00000110 (2진수) 첫 번째 바이트는 MSB가 1이고 1의 데이터를 가진다. 첫 번째 바이트의 MSB가 1인 것에 의해 두 번째 바이트도 살펴봐야 되는 상황이 되었는데, 두 번째 바이트의 MSB는 0이므로 더 이상의 추가적인 바이트를 사용하지 않는다. 따라서, (첫 번째 바이트의 하위 7비트) : (두 번째 바이트의 하위 7비트) = 1 0000110 (2진수) = 0x86 의 정수를 나타내는 varint임을 알 수 있다. (콜론(:)은 두 묶음의 7비트들을 나란히 이어붙이는 것을 의미한다.)
아래의 record 구조에 등장하게 되는 cell header와 record의 length of data header에서 이러한 varint 타입을 사용하여 값을 표현한다.
zurum, ⌜SQLite Record Recovery⌟, 『FORENSICINSIGHT SEMINAR』, page 19
cell offset을 통해 레코드에 접근한 후 순차적으로 Length of Record와 Row ID의 값을 구하고 이어서 Length of Data Header도 구할 수 있게 된다. 이때 구하게 되는 Data Header의 길이는 Length of Data Header 필드가 차지하는 길이도 포함된 값이므로, data field만의 길이를 구하기 위해서는 Length of Data Header의 값에서 이 필드가 차지하는 길이만큼을 빼주어야 한다.
이러한 작업을 통해 data field의 갯수를 구하게 된 뒤에는 이 갯수만큼 data header의 값을 순차적으로 읽고 다시 그 값만큼의 데이터를 읽어 나가는 방식으로 데이터를 파싱하면 된다.
그 과정에서 만나게 되는 data header의 size of field에는 각 칼럼에 해당하는 데이터 타입 및 크기에 대한 정보가 저장되어 있다. 각 값에 따른 데이터 타입 및 크기에 대한 정보는 다음의 표를 참고하면 알 수 있다.
이 표의 식별값은 10진수임에 유의하도록 한다..
여기까지의 정보를 이용하면 아래와 같이 record 내의 필드값을 파싱해낼 수 있다.
이 글에서 다룬 내용을 이용하여 하나의 테이블 내에 있는 하나의 레코드의 값을 구하는 흐름을 정리하면 아래와 같다.